CS:APP Chapter 9 Summary 💾
Recently, I’ve been studying CS:APP - I’m posting my own summary of chapter 9 that I wrote up using Notion.
9.1 Physical and Virtual Addressing
9.1 Physical and Virtual Addressing
Physical Addressing
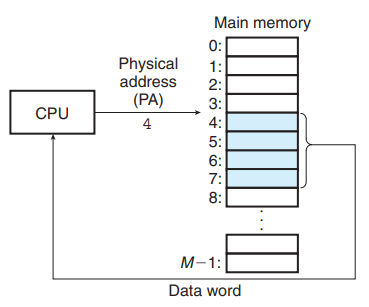
The main memory is organized as an array of M contiguous byte-size cells. Each byte has a unique physical address(PA).
Physical addressing refers to the approach that using physical address for CPU to access memory.
Virtual Addressing
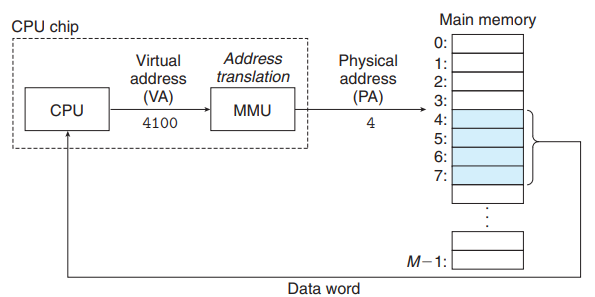
With virtual addressing, the CPU accesses main memory by generating virtual address(VA).
Virtual address is converted to the appropriate physical address before being sent to main memory - The memory management unit (MMU) translates virtual addresses using a lookup table stored in main memory whose contents are managed by the OS.
9.2 Address Spaces
9.2 Address Spaces
The CPU generates virtual addresses from an address space of addresses called the virtual address space : {0, 1, 2, ..., N - 1}. → n-bit address space.
A system also has a physical address space that corresponds to the M bytes of physical memory in the space : {0, 1, 2, ..., M - 1}.
Each byte of main memory has a virtual address chosen from the virtual address space, and a physical address chosen from the physical address space.
9.3 VM as a Tool for Caching
9.3 VM as a Tool for Caching
Virtual Page
Virtual memory is organized as an array of N contiguous byte-size cells stored on disk.
Virtual memory is partitioned into fixed-size blocks called virtual pages (VPs). Similarly, physical memory is partitioned into physical pages (PPs).
Each virtual page and physical page is bytes in size.
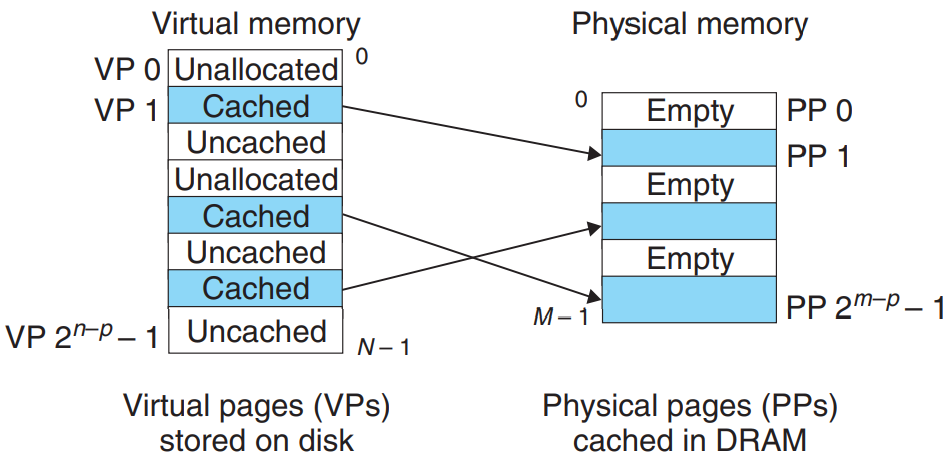
The set of virtual pages is partitioned into 3 disjoint subsets:
- Unallocated : Pages that have not yet been allocated by the VM system. - don’t occupy any space on disk.
- Cached : Allocated pages that are cached in physical memory.
- Uncached : Allocated pages that are not cached in physical memory.
DRAM Cache Organization
The term DRAM cache denotes the VM system’s cache that caches virtual pages in main memory.
DRAM cache’s large miss penalty & the expense of accessing the first byte on disk →
- Virtual pages tend to be large.
- DRAM caches are fully associative → Any virtual page can be placed in any physical page.
- OS use much more sophisticated replacement algorithms for DRAM caches.
- DRAM caches always use write-back instead of write-through.
Page Tables
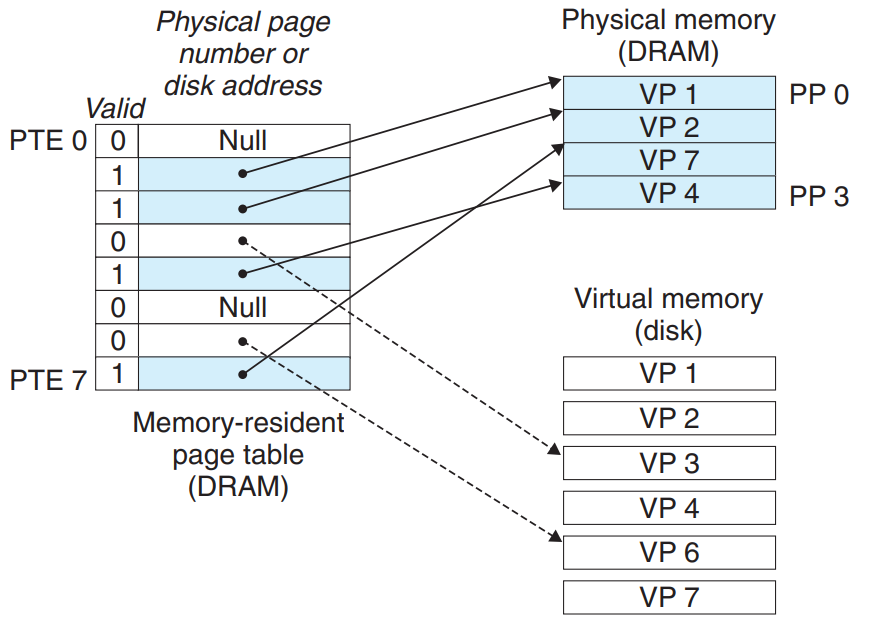
Virtual pages are managed by a combination of OS software, address translation hardware in the MMU, and a page table in physical memory that maps virtual pages to physical pages.
The address translation hardware reads the page table to convert a virtual address to a physical address.
The OS maintains the page table, and transfer pages back and forth between disk and DRAM.
The page table is an array of page table entries (PTEs). Each PTE consists of a valid bit and an n-bit address field.
The valid bit indicates whether the virtual page is currently cached in DRAM:
- The valid bit is set → the address field = the start of the corresponding physical page in DRAM where the virtual page is cached.
- The valid bit is unset
- A null address → the virtual page is unallocated.
- Otherwise → the address points to the start of the virtual page on disk.
Page Hits
- The address translation hardware uses the virtual address as an index to locate PTE and read it from memory.
- The valid bit is set → Page Hit
- The address translation hardware uses the physical memory address in the PTE to construct the physical address of the word.
Page Faults
A DRAM cache miss is known as a page fault.
- The address translation reads PTE from memory.
- The valid bit is unset → Page Fault
- The page fault exception invokes a page fault exception handler in the kernel.
- The kernel selects a victim page.
- If the victim page is modified, the kernel copies it back to disk.
- The kernel modifies the page table entry for the victim page.
- The kernel copies missed page from disk to memory, updates PTE, and then returns.
- When the handler returns, the kernel restarts the faulting instruction → Page Hit
Allocating Pages
Allocating pages is done by creating room on disk and updating PTE to point to the newly created page on disk.
Locality to the Rescue Again
In practice, virtual memory works well mainly because of locality.
After an initial overhead where the working set is paged into memory, subsequent references to the working set result in hits, with no additional disk traffic.
However, if the working set size exceeds the size of physical memory, the program can produce thrashing.
9.4 VM as a Tool for Memory Management
9.4 VM as a Tool for Memory Management
OS provide a separate page table, and thus a separate virtual address space, for each process.
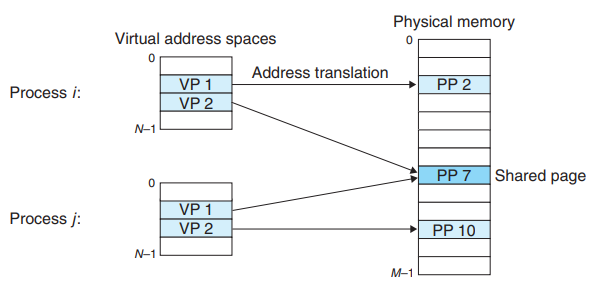
Multiple virtual pages can be mapped to the same shared physical page.
VM simplifies linking and loading, the sharing of code and data, and allocating memory to applications :
Simplifying linking
- Separate address space → Each process use the same basic format for its memory image.
- Uniformity simplifies the design and implementation of linkers.
- Linker can produce fully linked executables that are independent of the ultimate location of the code and data in physical memory.
Simplifying loading
- Linux loader loading
.text&.datasections of an object file into a newly created process :- Linux loader allocates virtual pages for the code and data segments.
- Linux loader marks them as invalid (not cached).
- Linux loader points their page table entries to the appropriate locations in the object file.
- The data are paged in automatically by the VM system the first time each page is referenced. (When CPU fetches an instruction, or an executing instruction references a memory location.)
- Memory mapping : Mapping a set of contiguous virtual pages to an arbitrary location in an arbitrary file
- Linux provides a system call
mmap- allows application programs to do their own memory mapping. (Section 9.8)
- Linux loader loading
Simplifying sharing
- In some instances processes need to share code and data:
- Every process must call the same OS kernel code.
- Every C program makes calls to routines in the standard C library. (example :
printf)
- OS can arrange for multiple processes to share a single copy of code by mapping the appropriate virtual pages in different processes to the same physical pages.
- In some instances processes need to share code and data:
Simplifying Memory Allocation
- When a program running in a user process requests additional heap space (example :
malloc) :- OS allocates an appropriate number, k, of contiguous virtual memory pages.
- OS maps them to k arbitrary physical pages located anywhere in physical memory.
There is no need for OS to locate k contiguous pages of physical memory. - The pages can be scattered randomly.
- When a program running in a user process requests additional heap space (example :
9.5 VM as a Tool for Memory Protection
9.5 VM as a Tool for Memory Protection
Rules for Protecting Memory
- A user process shouldn’t be allowed to modify its read-only code section.
- A user process shouldn’t be allowed to read or modify any of the code and data in the kernel.
- A user process shouldn’t be allowed to read or write the private memory of other processes.
- A user process shouldn’t be allowed to modify any virtual pages that are shared with other processes, unless all parties explicitly allow it.
Adding Permission Bits to PTE
Add three permission bits to each PTE to control access to the contents of a virtual page.
- SUP bit indicates whether processes must be running in kernel (supervisor) mode to access the page. (user process can access only page where SUP bit = 0)
- READ and WRITE bits control read and write access to the page.
If an instruction violates these permissions (segmentation fault), CPU triggers a general protection fault handler in the kernel. - sends a SIGSEGV signal to the offending process.
9.6 Address Translation
9.6 Address Translation
Address Translation
Address translation is a mapping between the elements of an N-element virtual address space (VAS) and an M-element physical address space (PAS),
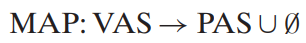
where
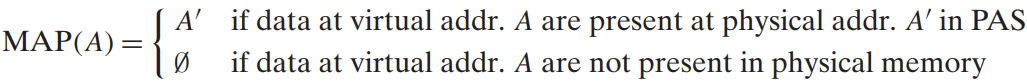
Address translation with a page table
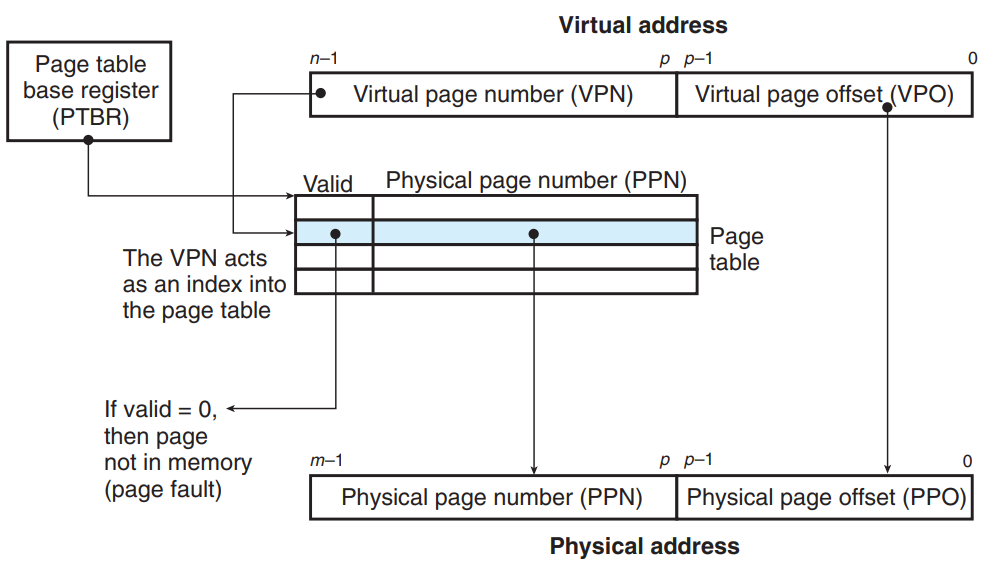
MMU uses the page table to perform address translation.
- The page table base register (PTBR) points to the current page table.
- n-bit virtual address consists of a p-bit virtual page offset (VPO) & an (n-p)-bit virtual page number (VPN).
- VPN is used for MMU to select the appropriate PTE. (example : VPN 0 selects PTE 0)
- Corresponding m-bit physical address is the concatenation of physical page number (PPN) & physical page offset (PPO).
- PPN is from the PTE selected using VPN.
- PVO is identical to the VPO. (Physical and virtual pages are both P bytes.)
- The steps the CPU hardware performs when there is a page hit.
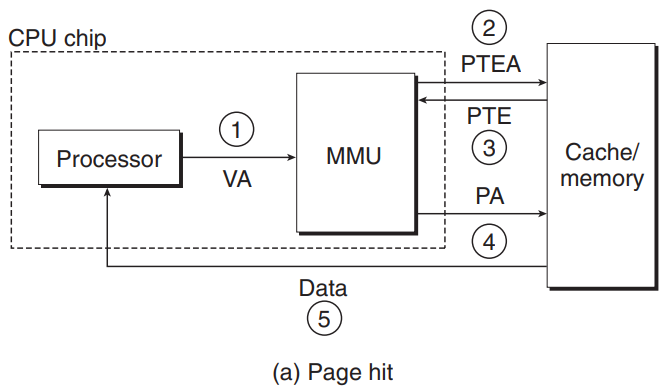
- The processor generates a VA and sends it to the MMU.
- The MMU generates the PTE address (PTEA) and requests it from the cache/main memory.
- The cache/main memory returns the PTE to the MMU.
- The MMU constructs the physical address (PA) and sends it to the cache/main memory.
- The cache/main memory returns the requested data word to the processor.
- The steps the CPU hardware & OS kernel performs when there is a page fault.
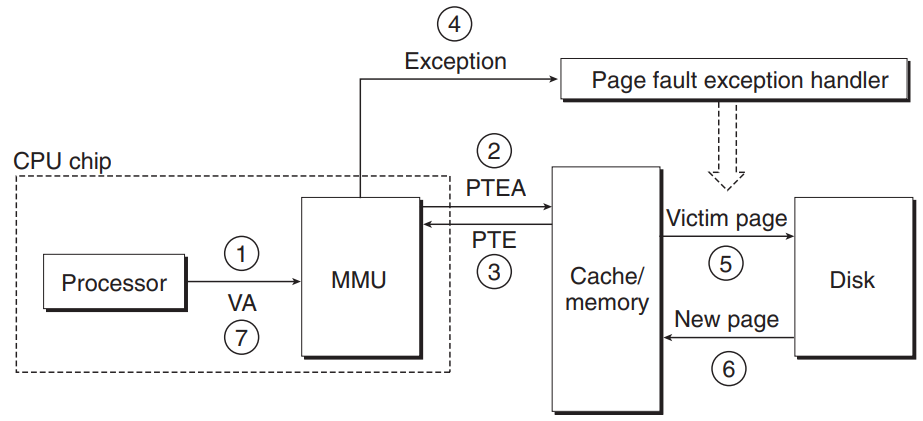
- The processor generates a VA and sends it to the MMU.
- The MMU generates the PTE address (PTEA) and requests it from the cache/main memory.
- The cache/main memory returns the PTE to the MMU.
- The valid bit in the PTE is zero → MMU triggers an exception → A page fault exception handler in OS kernel takes control.
- The fault handler identifies a victim page in physical memory, and pages it out to disk if it has been modified.
- The fault handler pages in the new page and updates the PTE in memory.
- The fault handler returns to the original process, restarting the faulting instruction. → Page hit
Integrating Caches and VM
Most system that uses both VM and SRAM caches uses physical addressing to access the SRAM cache:
- It is straightforward for multiple processes to have blocks in the cache at the same time, and to share blocks from the same virtual pages.
- The cache doesn’t have to deal with protection issues - access rights are checked as part of the address translation process.
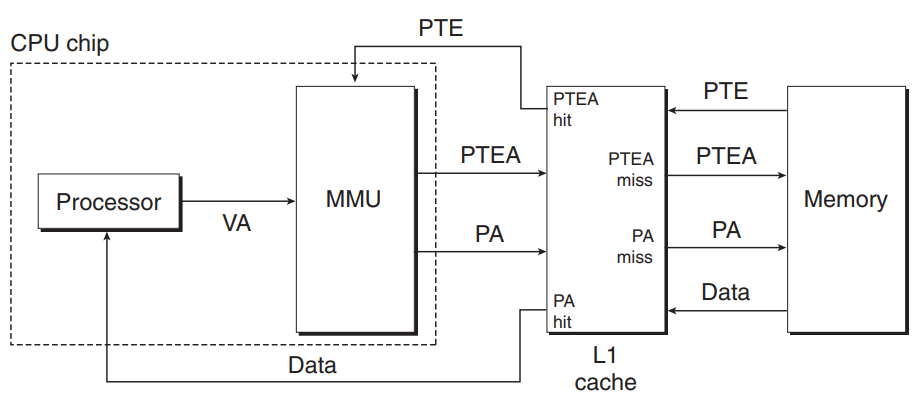
In a system that uses both VM and SRAM cache, the address translation occurs before the cache lookup.
PTEs can be cached just like any other data words.
Speeding Up Address Translation with a TLB
By including a small cache of PTEs in the MMU called a translation lookaside buffer (TLB), we can speed up the address translation.
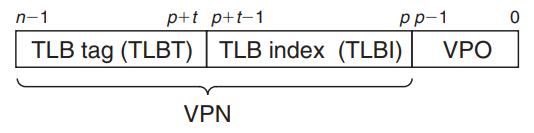
- TLB is a small, virtually addressed cache where each line holds a block consisting of a single PTE.
- The index and tag fields for TLB are extracted from VPN.
- If the TLB has sets, then the TLB index (TLBI) consists of the t least significant bits of VPN, and the TLB tag (TLBT) constis of the remaining n-p-t bits in the VPN.
- TLB hit & miss
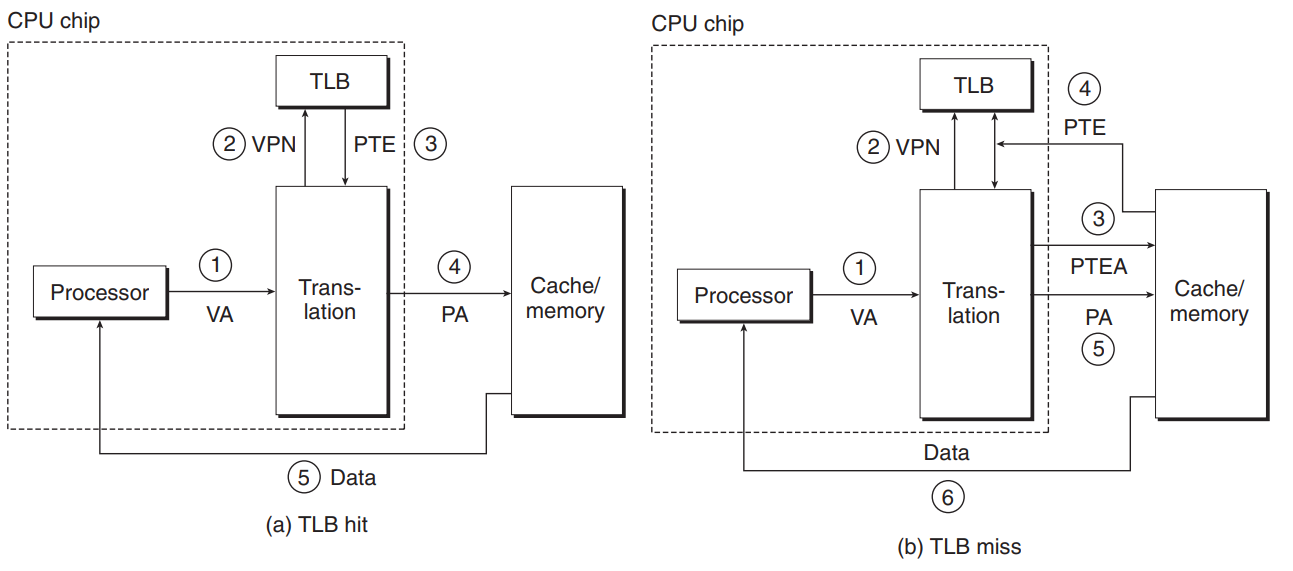
- The steps when there is a TLB hit
- The CPU generates a VA.
- The MMU fetches the appropriate PTE from TLB.
- The MMU translates the VA to a PA and sends it to the cache/main memory.
- The cache/main memory returns the requested data word to the CPU.
- When there is a TLB miss, The MMU must fetch the PTE from the L1 cache. The newly fetched PTE is stored in the TLB, possibly overwriting an existing entry.
Multi-Level Page Tables
Using a hierarchy of page tables is a common approach for compacting the page table to save memory.
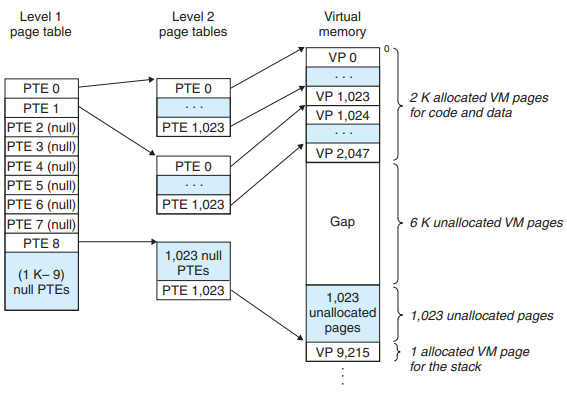
- Example of Multi-Level Page Tables
- Consider a 32-bit VAS (4 GB) partitioned into 4 KB pages, with PTE that are 4 bytes each.
- Suppose that the VAS has the form as shown in the figure.
- Level 1 Page Table
- Each PTE in level 1 is responsible for mapping a 4 MB chunk of the VAS, where each chunk consists of 1024 contiguous pages.
- The VAS is 4 GB → 1024 PTEs are sufficient to cover the entire space.
- If every page in chunk i is unallocated, then level 1 PTE i is null.
- If at least one page in chunk i is allocated, then level 1 PTE i points to the base of a level 2 page table.
- Level 2 Page Table
- Each PTE in level 2 is responsible for mapping a 4 KB page of virtual memory.
- Multi level page tables reduces memory requirements in two ways:
- If a PTE in the level 1 table is null, the corresponding level 2 page table doesn’t have to exist.
- Only the level 1 table needs to be in main memory at all times. Only the most heavily used level 2 page tables need to be cached in main memory.
- Address Translation with a k-level page table hierarchy
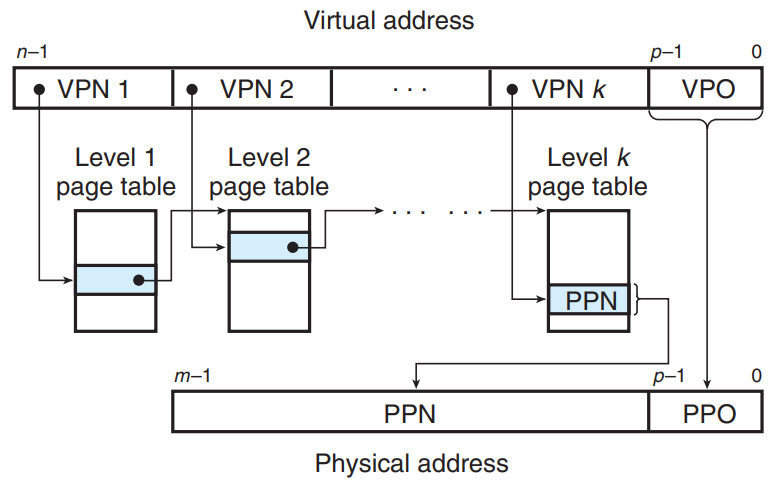
- The virtual address is partitioned into k VPNs and a VPO.
- Each PTE in a level j table, 1≤j≤k-1, points to the base of some page table at level j+1.
- Each PTE in a level k table contains either the PPN of some physical page or the address of a disk block.
- MMU must access k PTEs to construct the physical address.
- Example of Multi-Level Page Tables
Putting it Together: End-to-End Address Translation
- Assumptions on the system
- The memory is byte addressable.
- Memory accesses are to 1-byte words (not 4-byte words).
- Virtual addresses are 14 bits wide (n = 14)
- Physical addresses are 12 bits wide (m = 12).
- The page size is 64 bytes (P = 64). → p = 6
- The TLB is 4-way set associative with 16 total entries.
- The L1 d-cache is physically addressed and direct mapped, with a 4-byte line size and 16 total sets.
- Addressing for the system
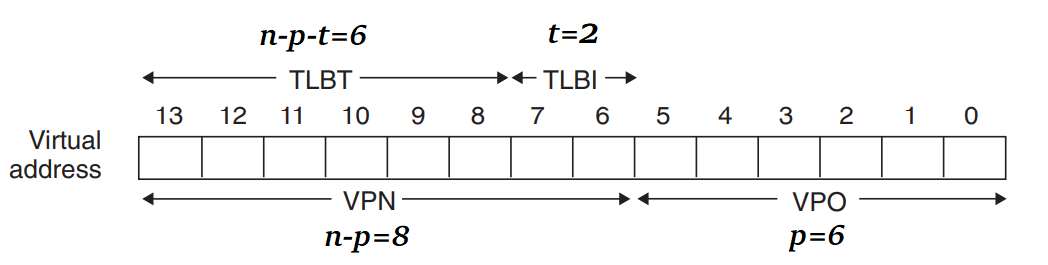
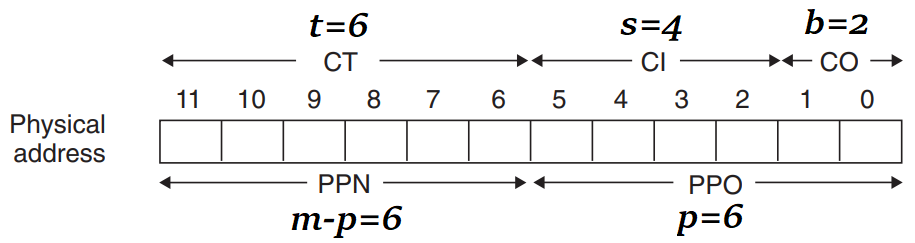
- TLB, Page Table, and Cache for the system
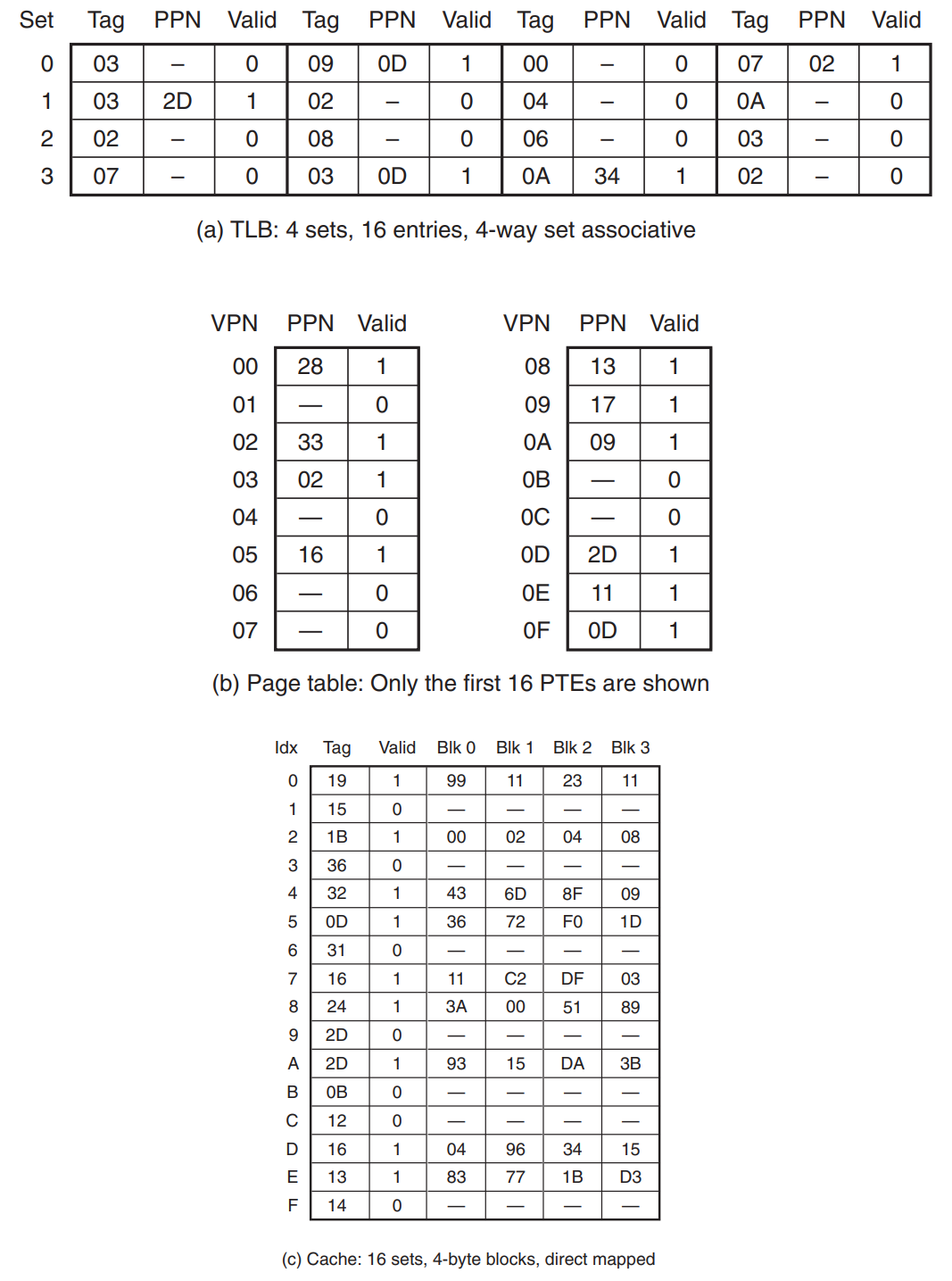
- In this system, the page table is a single-level design with a total of PTEs.
- Loading the byte at address
0x03d4- Get VPN, VPO, TLBT, TLBI from VA.
- TLB hit → Get PPN from TLB.
TLB miss → Fetch PPN from a PTE in the page table.
- The resulting PTE is invalid (Page fault) → Invoke the page fault handler to page in the appropriate page.
Otherwise → Construct PA. (PA = PPN + PPO)
- Get CT, CI, CO from PA.
- Cache hit → Read out the data from the cache.
Cache miss → Fetch the data from memory in the lower level.
- Assumptions on the system
9.7 Case Study: The Intel Core i7/Linux Memory System
9.7 Case Study: The Intel Core i7/Linux Memory System
The Core i7 Memory System
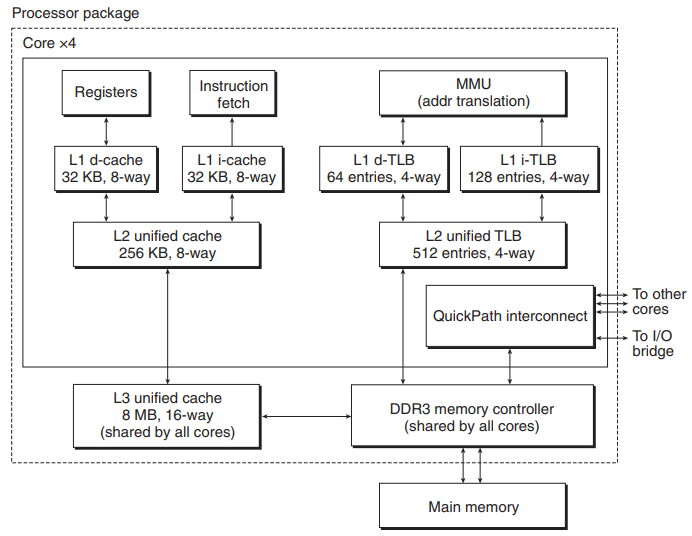
- The current Core i7 implementations support a 48-bit VAS & a 52-bit PAS, along with a compatibility mode that supports 32-bit VAS & PAS.
- The processor package includes 4 cores, a large L3 cache shared by all cores, and a DDR3 memory controller.
- Each core contains a hierarchy of TLBs, a hierarchy of d-caches and i-caches, and a set of fast point-to-point links.
- The fast point-to-point links are for communicating directly with the other cores and the external I/O bridge.
- The TLBs are virtually addressed, and 4-way set associative.
- The L1, L2, L3 caches are physically addressed, with a block size of 64 bytes.
- The L1, L2 caches are 8-way set associative, and L3 is 16-way set associative.
- The page size can be configured at start-up time as either 4KB or 4MB. Linux uses 4KB pages.
Core i7 Address Translation
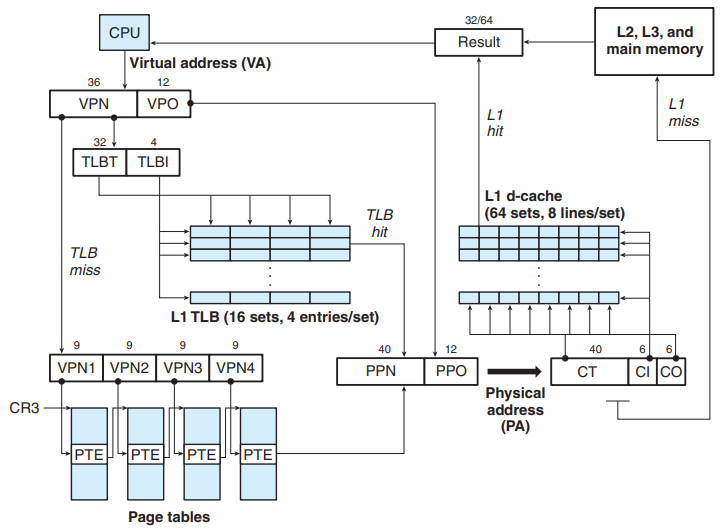
- The Core i7 uses a four-level page table hierarchy.
- When a Linux process is running, the page tables are all memory-resident, although the Core i7 architecture allows the page tables to be swapped in and out.
- The CR3 control register contains PA of the beginning of the level 1 page table. - The value of CR3 is part of each process context.
- Format of entry in a level 1, level 2, and level 3 page table
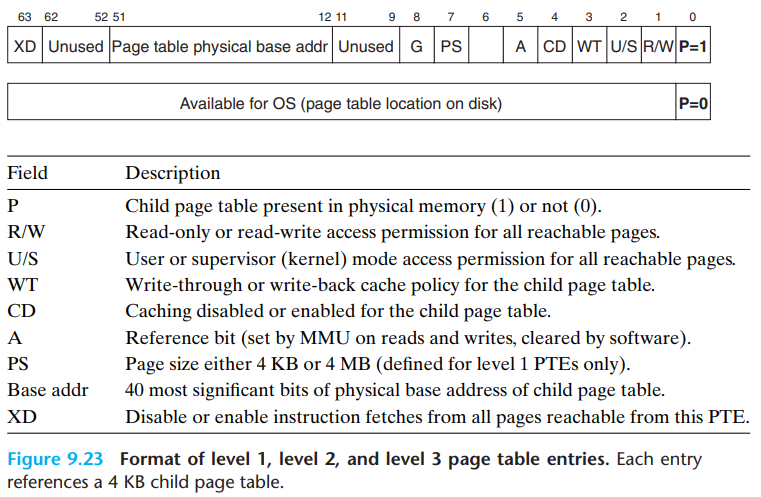
- P = 1 (always in Linux) → the address field contains a 40-bit PPN that points to the beginning of the appropriate page table.
- R/W bit : determines whether the contents of a page are read/write or read-only.
- U/S bit : determines whether the page can be accessed in user mode, or not (protected from user programs).
- XD bit : can be used to disable instruction fetches from individual memory pages. → can reduce the risk of buffer overflow attacks.
- A bit (reference bit) : is set each time a page is accessed.
- Format of entry in a level 4 page table

- P = 1 (always in Linux) → the address field contains a 40-bit PPN that points to the base of some page in physical memory.
- D bit (dirty bit) : is set each time the page is written to. → tells the kernel whether or not it must write back a victim page.
- The 36-bit VPN is partitioned into four 9-bit chunks, each of which is used as an offset into a page table.
- The CR3 register contains the physical address of the L1 page table.
Linux Virtual Memory System
Linux maintains a separate VAS for each process.
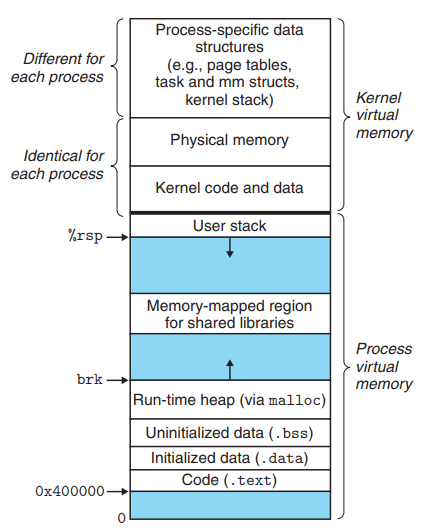
- The kernel virtual memory contains:
- Kernel code & data structures
- Physical pages that are shared by all processes.
- Linux also maps a set of contiguous virtual pages to the corresponding set of contiguous physical pages. → The kernel can access any specific location in physical memory conveniently. (example : when it needs to access page tables)
- Data that differ for each process
- Page tables
- Kernel stack
- Various data structures that keep track of the current organization of the VAS.
- The kernel virtual memory contains:
Linux Virtual Memory Areas
An area is a contiguous chunk of allocated VM whose pages are related in some way. (example : code seg, data seg, heap, …)
Any virtual page that is not part of some area doesn’t exist and can’t be referenced by the process.
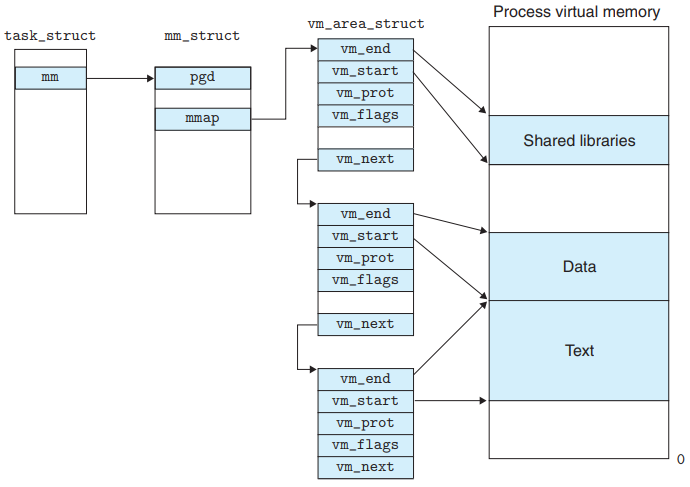
The kernel keeps track of the VMA in a process using the data structure in the figure.
- The kernel maintains a distinct task structure (
task_struct) for each process.- The elements of
task_structeither contain or point to all of the info that the kernel needs to run the process.- PID
- pointer to the user stack
- name of the executable object file
- PC
- One of the entry points to an
mm_structthat characterizes the current state of VM.
- The elements of
mm_struct's two fieldpgd: points to the base of the level 1 table. When the kernel run this process, it storespgdin the CR3 control register.
mmap: points to a list ofvm_area_structs(area struct), each of which characterizes an area of the current VAS.
vm_are_structvm_start: points to the beginning of the area.
vm_end: points to the end of the area.
vm_prot: describes the read/write permissions for all of the pages contained in the area.
vm_flags: describes (among other things) whether the pages in the area are shared with other processes or private to this process.
vm_next: points to the next area struct in the list.
- The kernel maintains a distinct task structure (
Linux Page Fault Exception Handling
When the MMU triggers a page fault while trying to translate some virtual address A, the kernel’s page fault handler performs the following steps :
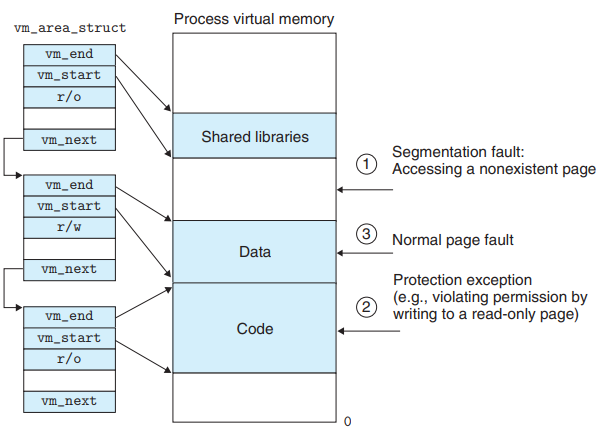
- Is VA A legal?
The handler checks if A lie within an area defined by some area struct.
- The fault handler searches the list of area structs, comparing A with
vm_start&vm_endin each area struct.
- A is not legal → The handler triggers a segmentation fault, which terminates the process.
- The fault handler searches the list of area structs, comparing A with
- Is the attempted memory access legal?
The handler checks if the process have permission to read, write, or execute the pages in the area.
- The attempted access is not legal → The handler triggers a protection exception, which terminates the process.
- Handle the page fault
At this point, the kernel knows that the page fault resulted from a legal operation on a legal VA. → The kernel handles the fault.
- The handler selects a victim page, swaps out the victim page if it’s dirty, swaps in the new page, and updates the page table.
- When the page fault handler returns, the CPU restarts the faulting instruction, which sends A to the MMU again.
- Is VA A legal?
9.8 Memory Mapping
9.8 Memory Mapping
Initializing the Contents of Virtual Memory Area
Linux initializes the contents of a virtual memory area by associating it with an object on disk. → Memory mapping
Areas can be mapped to one of two types of objects:
- Regular file in the Linux file system
- An area can be mapped to a contiguous section of a regular disk file. (example : executable object file)
- The file section is divided into page-size pieces, with each piece containing the initial contents of a virtual page.
- The CPU first touches the page → These virtual pages are actually swapped into physical memory. (demand paging)
- If the area is larger than the file section, the area is padded with zeros.
- Anonymous file
- An area can be mapped to an anonymous file that contains all binary zeros.
- The kernel performs the following steps for memory mapping:
- The CPU touches a virtual page in the area mapped to anonymous file.
- The kernel finds an appropriate victim page in PM, and swaps out it if it’s dirty.
- The kernel overwrites the victim page with binary zeros.
- The kernel updates the page table to mark the page as resident.
- Pages in areas that are mapped to anonymous files are sometimes called demand-zero pages.
In either case, once a virtual page is initialized, it is swapped back and forth between a special swap file maintained by the kernel.
The swap space bounds the total amount of VPs that can be allocated by the currently running processes.
- Regular file in the Linux file system
Shared Objects Revisited
In general, many processes have identical read-only code areas. (example : every C program requires functions from the standard C library.)
⇒ Memory mapping provides a clean mechanism for controlling how objects are shared by multiple processes.
An object can be mapped into an area of VM as either a shared object or a private object:
- Shared object
- Any changes made to the area are visible to any other processes that have also mapped the shared object into their VM.
- The changes are also reflected in the original object on disk.
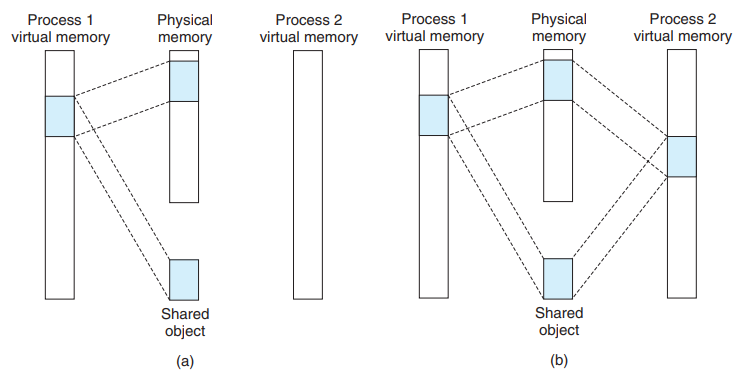
- Only a single copy of the shared object needs to be stored in PM, even though the object is mapped into multiple shared libraries.
- In the figure, the physical pages are being contiguous for convenience. - This is not true in general.
- Private object
- Changes made to the area are not visible to other processes.
- The changes are not reflected to the object on disk.
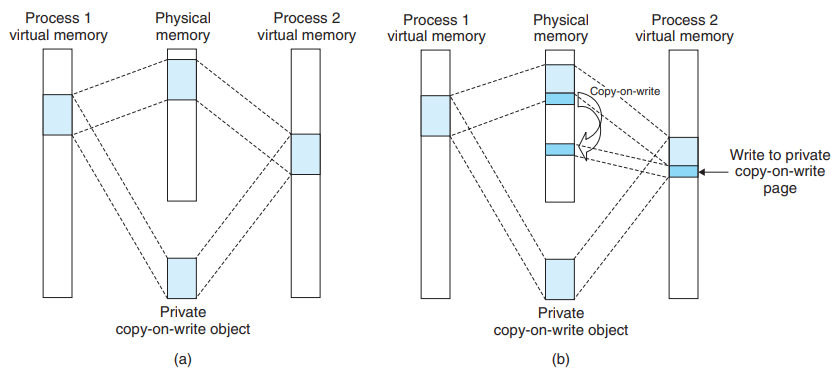
- Private objects are mapped into VM using a technique known as copy-on-write.
- A private object begins life in the same way as a shared object.
For each process that maps the private object, the PTEs for the corresponding area are flagged as read-only, and the area struct is flagged as private copy-on-write.
- As long as neither process attempts to write to its respective private area, they continue to share a single copy in physical memory.
- As soon as a process attempts to write to some page in the private area, the write triggers a protection fault.
- The fault handler creates a new copy of the page in physical memory, updates the PTE to point to the new copy and restores write permissions to the page.
- When the handler returns, the CPU re-executes the write, which now proceeds normally on the newly created page.
- A private object begins life in the same way as a shared object.
- Shared object
The
forkFunction RevisitedWhen the
forkfunction is called by the current process, it performs the following steps:- It creates exact copies of the current process’s
mm_struct, area structs, and page tables.
- It flags each page in both processes as read-only, and flags each area struct in both processes as private copy-on-write.
After the
forkreturns, if either of the processes performs any subsequent writes, the copy-on-write mechanism creates new pages.- It creates exact copies of the current process’s
The
execveFunction Revisited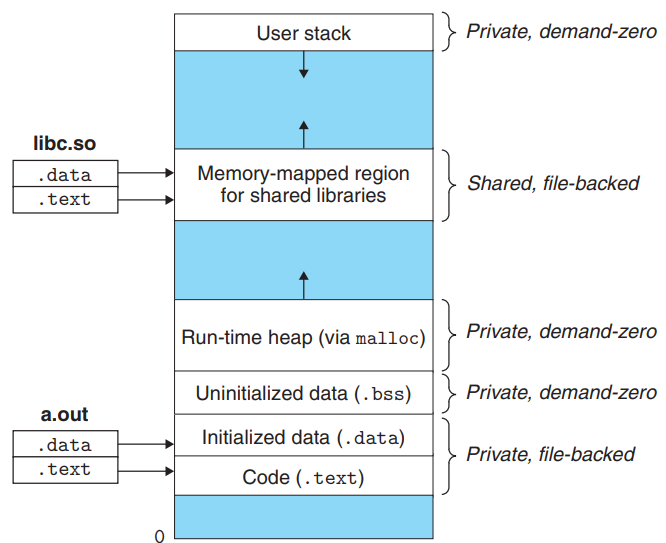
The
execveloads and runs the program by performing the following steps:- Delete existing area structs in the user virtual address space.
- Map private areas.
- Create new area structs for the code, data, bss, and stack areas of the new program.
- All of these new areas are private copy-on-write.
- The code and data areas are mapped to the
.textand.datasections.
- The bss area is demand-zero, mapped to an anonymous file whose size is contained in the object file.
- The stack and heap area are also demand-zero, initially of zero length.
- If the object file was linked with shared objects, these objects are dynamically linked into the program, and then mapped into the shared region of the user VAS.
- Set the PC in the current process’s context to point to the entry point in the code area.
User-Level Memory Mapping with the
mmapFunction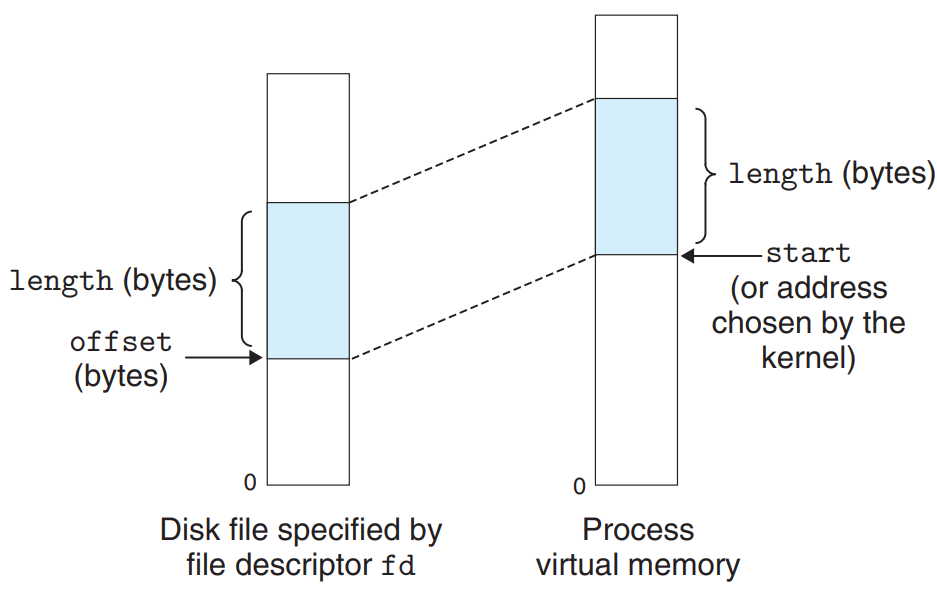
#include <unistd.h> #include <sys/main.h> void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);mmapasks the kernel to create a new VM area, preferably one that starts atstart, and to map a contiguous chunk of the object specified by file descriptorfdto the new area. (startis usually specified as NULL.)
- The contiguous object chunk has a size of
lengthbytes and starts at an offset ofoffsetbytes from the beginning of the file.
protcontains bits that describe the access permissions of the newly mapped VM area.PROT_EXEC: Pages in the area consist of instructions that may be executed by the CPU.
PROT_READ: Pages in the area may be read.
PROT_WRITE: Pages in the area may be written.
PROT_NONE: Pages in the area can’t be accessed.
flagsconsists of bits that describe the type of the mapped object.MAP_ANONis set : the mapped object is an anonymous object and the corresponding virtual pages are demand-zero.
MAP_PRIVATEis set : the mapped object is a private copy-on-write object.
MAP_SHAREDis set : the mapped object is a shared object.
bufp = Mmap(NULL, size, PROT_READ, MAP_PRIVATE|MAP_ANON, 0, 0);→ asks the kernel to create a new read-only, private, demand-zero area of VM containingsizebytes.
#include <unistd.h> #include <sys/main.h> void munmap(void *start, size_t length);munmapdeletes the area starting at virtual addressstartand consisting of the nextlengthbytes.
- Subsequent references to the deleted region result in segmentation fault.
9.9 Dynamic Memory Allocation
9.9 Dynamic Memory Allocation
Dynamic Memory Allocator
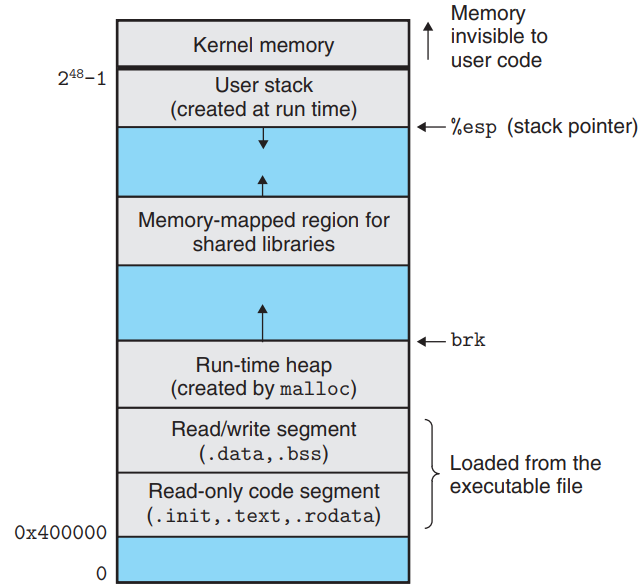
A dynamic memory allocator maintains an area of a process’s VM known as the heap.
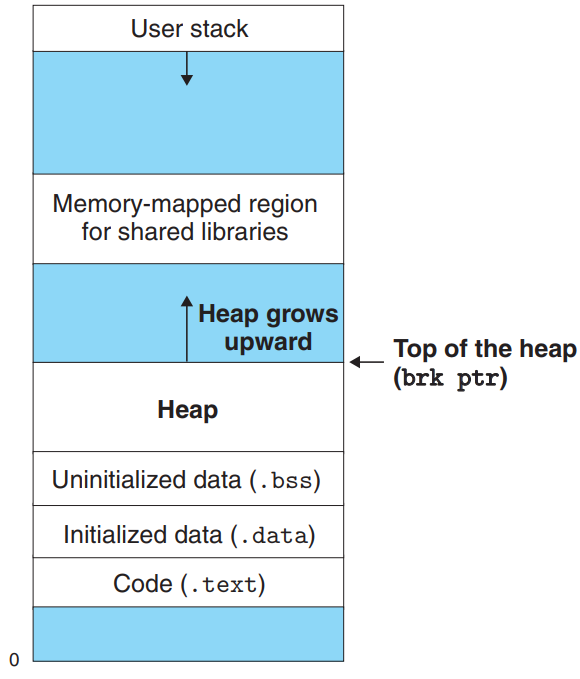
- The heap is an area of demand-zero memory that begins immediately after the uninitialized data area and grows upward.
- The kernel maintains a variable
brkthat points to the top of the heap for each process.
- The heap is maintained as a collection of various-size blocks.
- Each block is a contiguous chunk of VM that is either allocated or free.
- An allocated block remains allocated until it is freed either explicitly by the application or implicitly by the memory allocator itself.
- Allocator comes in two basic styles that differ about which entity is responsible for freeing allocated blocks.
- Explicit allocators require the application to explicitly free any allocated blocks. (example : C standard library provides an explicit allocator called the
mallocpackage.)
- Implicit allocators require the allocator to detect when an allocated block is no longer being used and then free the block. (example : garbage collectors) → Section 9.10
- Explicit allocators require the application to explicitly free any allocated blocks. (example : C standard library provides an explicit allocator called the
The
mallocandfreeFunctions -malloc,free,sbrk#include <stdlib.h> void *malloc(size_t size);- The
mallocreturns a pointer to a block memory of at leastsizebytes that is suitably aligned for any kind of data object.
- In 32-bit mode,
mallocreturns a block whose address is always a multiple of 8. In 64-bit mode, the address is always a multiple of 16.
- If
mallocencounters a problem, it returns NULL and setserrno.
mallocdoesn’t initialize the memory it returns. - Usecalloc, a thin wrapper around themallocthat initializes the allocated memory to zero.
- To change the size of a previously allocated block, use the
realloc.
#include <unistd.h> void *sbrk(intptr_t incr);- Dynamic memory allocators can allocate heap memory explicitly by using the
mmapandmunmap, or they can usesbrkfunction.
sbrkgrows or shrinks the heap by addingincrto the kernel’sbrkpointer.
- If successful, it returns the old value of
brk, otherwise it returns -1 and setserrnoto ENOMEM.
#include <stdlib.h> void free(void *ptr);- Programs free allocated heap blocks by calling the
free.
ptrmust point to the beginning of an allocated block that was obtained frommalloc,calloc, orrealloc.
- Allocating and freeing blocks with
malloc&free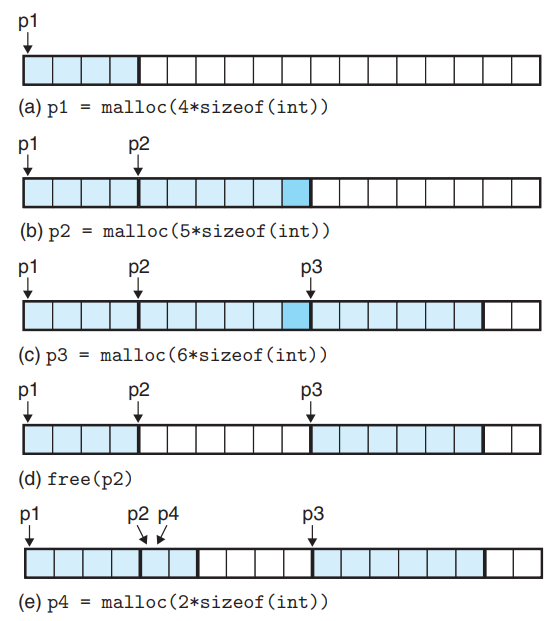
- (b) :
mallocpads the block with an extra word to keep the free block aligned on a double-word boundary. (b)
- (d) : After the
freereturns, the pointerp2still points to the freed block. Application should not usep2again until it is reinitialized by a new call tomalloc.
- (b) :
- The
Why Dynamic Memory Allocation?
Programs don’t know the sizes of certain data structures until the program actually runs. → Use dynamic memory allocation.
Allocator Requirements and Goals
- Allocator Requirements
- Handling arbitrary request sequences : Each free request must correspond to a currently allocated block obtained from a previous allocate request.
- Making immediate responses to requests : The allocator is not allowed to reorder or buffer requests in order to improve performance.
- Using only the heap : Any nonscalar data structures used by the allocator must be stored in the heap itself.
- Aligning blocks (alignment requirement)
- Not modifying allocated blocks : Allocators are not allowed to modify or move blocks once they are allocated.
- Allocator Goals
- Maximizing Throughput
- Maximizing Memory Utilization
- We use a peak utilization to characterize how efficiently an allocator uses the heap.
- The peak utilization over the first k + 1 requests, , is given by . ( = the current size of the heap, = the sum of the payloads of the currently allocated blocks)
- There is a tension between maximizing throughput and utilization.
- Allocator Requirements
Fragmentation
Fragmentation is the primary cause of poor heap utilization, which occurs when otherwise unused memory is not available to satisfy allocate requests.
- Internal Fragmentation
- Internal fragmentation occurs when an allocated block is larger than the payload.
- This happen for a number of reasons:
- The implementation of an allocator impose a minimum size on allocated blocks.
- The allocator increase the block size to satisfy alignment constraints.
- Internal fragmentation is quantified as the sum of the differences between the sizes of the allocated blocks and their payloads.
- External Fragmentation
- External fragmentation occurs when there is enough aggregate free memory to satisfy an allocate request, but no single free block is large enough to handle the request.
- External fragmentation is much more difficult to quantify - it also depends on the pattern of future requests.
- Allocators typically employ heuristics that attempt to maintain small numbers of larger free blocks rather than large numbers of smaller free blocks.
- Internal Fragmentation
Implementation Issues
A practical allocator with a better balance between throughput and utilization must consider the following issues:
- Free block organization : How do we keep track of free blocks?
- Placement : How do we choose an appropriate free block to place a newly allocated block?
- Splitting : What do we do with the remainder of the free block after placing a newly allocated block?
- Coalescing : What do we do with a block that has just been freed?
Implicit Free Lists
An implicit free lists is a simple free block organization.
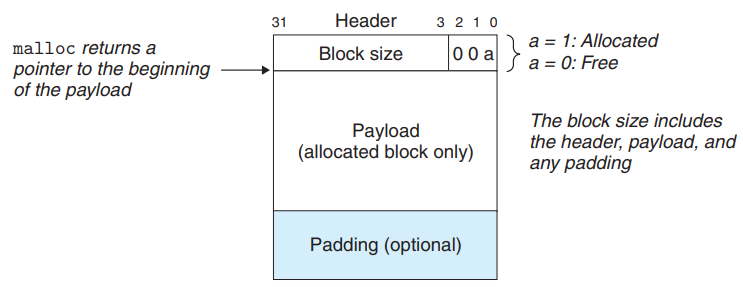
- A block consists of a one-word header, the payload, and possibly some additional padding.
- The header encodes the block size, and whether the block is allocated or free.
- If we impose a double-word alignment constraint, the block size is always a multiple of 8 and the 3 low-order bits of the size are always zero. → Store only the 29 high-order bits of the size, and use remaining 3 bits to encode other information.
- In this case, use the leas significant of these bits to indicate whether the block is allocated or free.
- The free blocks are linked implicitly by the size fields in the headers → This organization is called an implicit free list.

- The allocator can traverse the entire set of free blocks by traversing all of the blocks in the heap.
- There is a specially marked end block - in this example, a terminating header with the allocated bit set and a size of zero.
- Advantage → Simplicity.
- Disadvantage → The cost of any operation that requires a search of the free list will be linear in the total number of allocated and free blocks in the heap.
- Minimum Block Size
- The system’s alignment requirement & the allocator’s choice of block format impose a minimum block size.
- IF we assume a double-word alignment requirement, the size of each block must be a multiple of two words (8 bytes). → The implicit free list’s block format induces a minimum block size of two words : one word for the header, and another to maintain the alignment requirement. → Even if the application were to request a single byte, the allocator would still create a two-word block.
Placing Allocated Blocks
When requested a block of k bytes, the allocator searches the free list for a free block that is large enough to hold the requested block according to the placement policy.
- First fit
- searches the free list from the beginning and chooses the first free block that fits.
- tends to retain large free blocks at the end of the list.
- tends to leave splinters of small free blocks toward the beginning of the list, which will increase the search time for larger blocks.
- Next fit
- starts each search where the previous search left off.
- can run significantly faster than first fit, especially if the front of the list becomes littered with many splinters.
- suffers from worse memory utilization than first fit.
- Best fit
- examines every free block and chooses the free block with the smallest size that fits.
- enjoys better memory utilization than either first fit or next fit.
- with simple free list organizations such as the implicit free list, requires an exhaustive search of the heap. → use more sophisticated organization
- First fit
Splitting Free Blocks
The allocator also has to make policy decision about how much of the free block to allocate.
Using the entire free block is simple and fast, but can introduce internal fragmentation.
If the placement policy tends to produce good fits, then some additional internal fragmentation might be acceptable.
If the fit is not good, the allocator usually opt to split the free block into two parts. (allocated block & new free block)
Getting Additional Heap Memory
If the allocator is unable to find a fit for the requested block:
- The allocator try to create some larger free blocks by merging (coalescing) free blocks that are physically adjacent in memory.
- If this doesn’t yield a sufficiently large block, or if the free blocks are already maximally coalesced, the allocator asks the kernel for additional heap memory by calling the
sbrk.
- The allocator transforms the additional memory into one large free block, inserts the block into the free list, and then places the requested block in this new block.
Coalescing Free Blocks
After freeing an allocated block, there can be a false fragmentation, where there is a lot of available free memory chopped up into small, unusable free blocks.
→ Need to merge adjacent free blocks. (coalescing)
- Immediate coalescing
- merging any adjacent blocks each time a block is freed.
- can be performed in constant time
- can introduce a form of thrashing where a block is repeatedly coalesced and then split soon thereafter, with some request patterns.
- Deferred coalescing
- waiting to coalesce free blocks at some later time. (example : until some allocation request fails)
- fast allocators often opt for some form of deferred coalescing.
- Immediate coalescing
Coalescing with Boundary Tags
To coalesce the previous block efficiently, use a technique known as boundary tags : add a footer (the boundary tag) at the end of each block, where the footer is a replica of the header.
→ The allocator can determine the starting location and status of the previous block by inspecting its footer, which is always one word away from the start of the current block.
- Case 1 : prev and next allocated
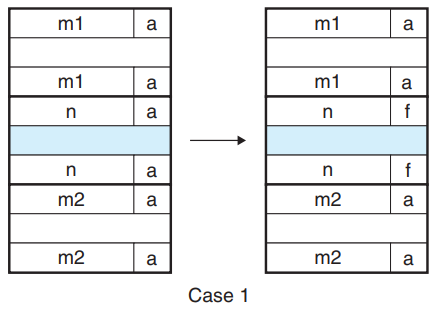
- The status of the current block is changed from allocated to free.
- Case 2: prev allocated, next free
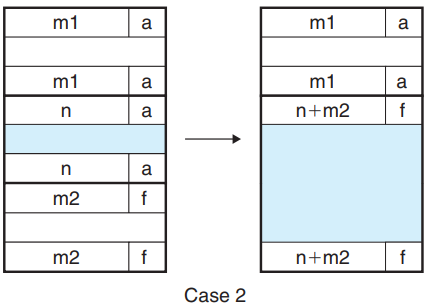
- The header of current block and the footer of the next block are updated with the combined sizes of the two blocks.
- Case 3: prev free, next allocated
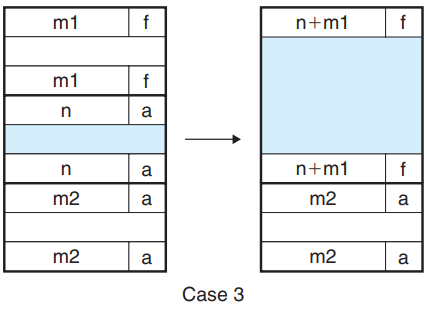
- The header of the previous block and the footer of the current block are updated with the combined sizes of the two blocks.
- Case 4: next and prev free
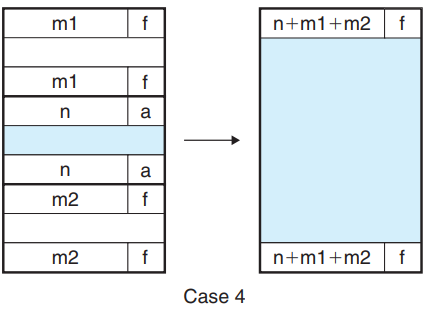
- The header of the previous block and the footer of the next block are updated with the combined sizes of the three blocks.
We can eliminate the footer in allocated blocks for optimization - Instead, we can store the allocated/free bit of the previous block in one of the excess low-order bits of the current block. However, the free blocks would still need footers.
- Case 1 : prev and next allocated
Putting It Together: Implementing a Simple Allocator
Implement a simple allocator based on an implicit free list with immediate boundary-tag coalescing.
The maximum block size is . The code is 64-bit clean, running without modification in 32-bit or 64-bit processes.
General Allocator Design
Our allocator uses a model of the memory system provided by the
memlib.cpackage./* Private global variables */ static char *mem_heap; /* Points to first byte of heap */ static char *mem_brk; /* Points to last byte of heap plus 1 */ static char *mem_max_addr; /* Max legal heap addr plus 1 */ /* * mem_init - INitialize the memory system model */ void mem_init(void){ mem_heap = (char *)Malloc(MAX_HEAP); mem_brk = (char *)mem_heap; mem_max_addr = (char *)(mem_heap + MAX_HEAP); } /* * mem_sbrk - Simple model of the sbrk function. Extends the heap * by incr bytes and returns the start address of the new area. In * this model, the heap cannot be shrunk. */ void *mem_sbrk(int incr){ char *old_brk = mem_brk; if( (incr < 0) || ((mem_brk + incr) > mem_max_addr) ){ errno = ENOMEM; fprintf(stderr, "ERROR: mem_sbrk failed. Ran out of memory...\n"); return (void *)-1; } mem_brk += incr; return (void *)old_brk; }mem_initmodels the VM available to the heap as a large double-word aligned array of bytes.
- The bytes between
mem_heapandmem_brkrepresent allocated VM.
- The bytes following
mem_brkrepresent unallocated VM.
- The allocator requests additional heap memory by calling the
mem_sbrk.
- The allocator exports three functions to application programs:
extern int mm_init(void); extern void *mm_malloc(size_t size); extern void mm_free(void *ptr);mm_mallocandmm_freehave the same interfaces and semantics as their system counterparts.
- The allocator uses the invariant form of the implicit free list.
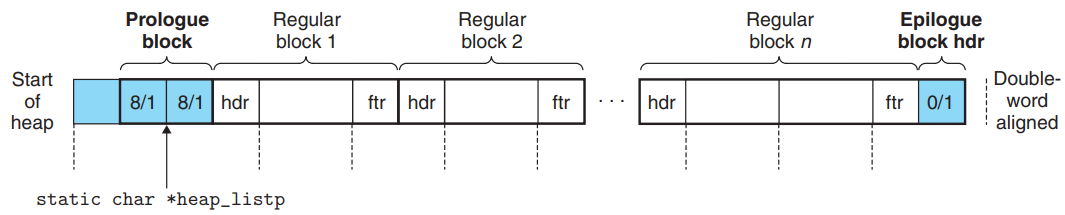
- The first word is an unused padding word aligned to a double-word boundary.
- The padding is followed by a special prologue block, which is an 8-byte allocated block consisting of only a header and a footer.
- The heap always ends with a special epilogue block, which is a zero-size allocated block that consists of only a header.
- The allocator uses a single private (
static) global variable,heap_listp, that always points to the prologue block.
Basic Constants and Macros for Manipulating the Free List
/* Basic constants and macros */ #define WSIZE 4 /* Word and header/footer size (bytes) */ #define DSIZE 8 /* Double word size (bytes) */ #define CHUNKSIZE (1<<12) /* Extend heap by this amount (bytes) */ #define MAX(x, y) ((x) > (y)? (x) : (y)) /* Pack a size and allocated bit into a word */ #define PACK(size, alloc) ((size) | (alloc)) /* Read and write a word at address p */ #define GET(p) (*(unsigned int *)(p)) #define PUT(p) (*(unsigned int *)(p) = (val)) /* Read the size and allocated fields from address p */ #define GET_SIZE(p) (GET(p) & ~0x7) #define GET_ALLOC(p) (GET(p) & 0x1) /* Given block ptr bp, compute address of its header and footer */ #define HDRP(bp) ((char *)(bp) - WSIZE) #define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE) /* Given block ptr bp, compute address of next and previous blocks */ #define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp) - WSIZE))) #define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE)))HDRPandFTRPoperate on block pointers (bp) that point to the first payload byte.
- We can use the macro in various ways to manipulate the free list (example : determining the size of the next block -
GET_SIZE(HDRP(NEXT_BLKP(bp)));)
Creating the Initial Free List
int mm_init(void){ /* Create the initial empty heap */ if ((heap_listp = mem_sbrk(4*WSIZE)) == (void *)-1) return -1; PUT(heap_listp, 0); /* Alignment padding */ PUT(heap_listp + (1*WSIZE), PACK(DSIZE, 1)); /* Prologue header */ PUT(heap_listp + (2*WSIZE), PACK(DSIZE, 1)); /* Prologue footer */ PUT(heap_listp + (3*WSIZE), PACK(0, 1)); /* Epilogue header */ heap_listp += (2*WSIZE); /* Extend the empty heap with a free block of CHUNKSIZE bytes */ if (extend_heap(CHUNKSIZE/WSIZE) == NULL) return -1; return 0; } static void *extend_heap(size_t words){ char *bp; size_t size; /* Allocate an even number of words to maintain alignment */ size = (words % 2) ? (words+1) * WSIZE : words * WSIZE; if ((long)(bp = mem_sbrk(size)) == -1) return NULL; /* Initialize free block header/footer and the epilogue header */ PUT(HDRP(bp), PACK(size, 0)); /* Free block header */ PUT(FTRP(bp), PACK(size, 0)); /* Free block footer */ PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); /* New epilogue header */ /* Coalesce if the previous block was free */ return coalesce(bp); }mm_initgets 4 words from the memory system and initializes them to create the empty free list. It then callsextend_heap.
extend_heapextends the heap bywordsbytes and creates the initial free block.extend_heapis invoked when the heap is initialized, and whenmm_mallocis unable to find a suitable fit.
extend_heaprounds up the requested size to the nearest multiple of 2 words (8 bytes), and requests the additional heap space from the memory system.
- The remainder of the
extend_heapinitializes free block header, footer, and the epilogue header.
- Finally,
extend_heapcall thecoalesceto merge the possible two free blocks, and return the block pointer of the merged blocks.
Freeing and Coalescing Blocks
void mm_free(void *bp){ size_t size = GET_SIZE(HDRP(bp)); PUT(HDRP(bp), PACK(size, 0)); PUT(FTRP(bp), PACK(size, 0)); coalesce(bp); } static void *coalsece(void *bp){ size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp))); size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp))); size_t size = GET_SIZE(HDRP(bp)); if (prev_alloc && next_alloc) { /* Case 1 */ return bp; } else if (prev_alloc && !next_alloc) { /* Case 2 */ size += GET_SIZE(HDRP(NEXT_BLKP(bp))); PUT(HDRP(bp), PACK(size, 0)); PUT(FTRP(bp), PACK(size, 0)); } else if (!prev_alloc && next_alloc) { /* Case 3 */ size += GET_SIZE(HDRP(PREV_BLKP(bp))); PUT(FTRP(bp), PACK(size, 0)); PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); bp = PREV_BLKP(bp); } else { /* Case 4 */ size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp))); PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0)); bp = PREV_BLKP(bp); } return bp; }mm_freefrees the requested block (bp) and then merges adjacent free blocks using the boundary-tags coalescing technique.
- In
coalesce, the prologue and epilogue blocks allow us to ignore the potentially troublesome edge conditions.
Allocating Blocks
void *mm_malloc(size_t size){ size_t asize; /* Adjusted block size */ size_t extendsize; /* Amount to extend heap if no fit */ char *bp; /* Ignore spurious requests */ if (size == 0) return NULL; /* Adjust block size to include overhead and alignment reqs. */ if (size <= DSIZE) asize = 2*DSIZE; /* 8 bytes for alginment requirement, and another 8 bytes for header and footer. */ else asize = DSIZE * ((size + (DSIZE) + (DSIZE-1)) / DSIZE); /* Add 8 bytes for header and footer, then round up to the nearest multiple of 8. */ /* Search the free list for a fit */ if ((bp = find_fit(asize)) != NULL) { place(bp, asize); return bp; } /* No fit found. Get more memory and place the block */ extendsize = MAX(asize, CHUNKSIZE); if ((bp = extend_heap(extendsize/WSIZE)) == NULL) return NULL; place(bp, asize); return bp; }find_fitperform a first-fit search of the implicit free list.
static void *find_fit(size_t asize){ char *bp = heap_listp; while(GET_SIZE(HDRP(bp))){ if(!GET_ALLOC(HDRP(bp)) && GET_SIZE(HDRP(bp)) >= asize) return bp; bp = NEXT_BLKP(bp); } return NULL; }placein place the requested block at the beginning of the free block, then splits only if the size of the remainder would equal or exceed the minimum block size (16 bytes).
static void place(void *bp, size_t asize){ int csize = GET_SIZE(HDRP(bp)); if (csize - asize >= 2 * DSIZE) { PUT(HDRP(bp), PACK(asize, 1)); PUT(FTRP(bp), PACK(asize, 1)); bp = NEXT_BLKP(bp); PUT(HDRP(bp), PACK(csize-asize, 0)); PUT(FTRP(bp), PACK(csize-asize, 0)); } else { PUT(HDRP(bp), PACK(csize, 1)); PUT(FTRP(bp), PACK(csize, 1)); } }
Explicit Free Lists
For the implicit free list, block allocation time is linear in the total number of heap blocks. → Organize the free blocks into some form of explicit data structure.
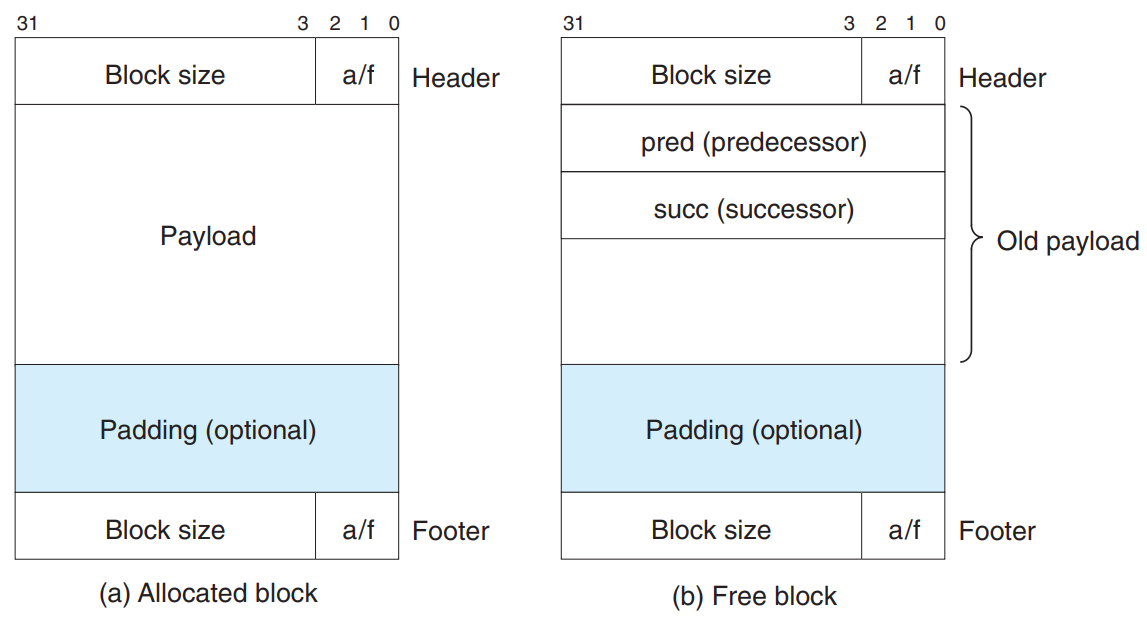
- The body of a free block is not needed → the pointers that implement the data structure can be stored within the body of the free blocks.
- For example, the heap can be organized as a doubly linked free list by including a
predandsuccpointer in each free block.
- Using a doubly linked list reduces the first-fit allocation time from linear in the total number of blocks to linear in the number of free blocks.
- The time to free a block can be either linear or constant depending on how we order the blocks in the free list:
- LIFO ordered (inserting newly freed blocks at the beginning of the list)
- With a LIFO ordering and a first-fit placement policy, freeing a block can be performed in constant time.
- If boundary tags are used, coalescing can be performed in constant time.
- Address ordered :
- Freeing a block requires a linear-time search.
- Address-ordered first fit enjoys better memory utilization than LIFO-ordered first fit.
- LIFO ordered (inserting newly freed blocks at the beginning of the list)
- Free blocks must be large enough to contain all of the necessary pointers, as well as the header and a footer. → A larger minimum block size → Increased potential for internal fragmentation.
Segregated Free Lists
An allocator that uses a single free list requires time linear in the number of free blocks to allocate a block → Use a segregated storage.
The segregated storage maintain multiple free lists, where each list holds blocks that are roughly the same size. The storage partition the set of all possible block sizes into equivalence classes called size classes.
The allocator maintains an array of free lists, with one free list per size class, ordered by increasing size. When the allocator needs a block of size n, it searches the appropriate free list. If it can’t find a block that fits, it searches the next list, and so on.
There are many variants of segregated storage:
- Simple Segregated Storage
- With simple segregated storage, the free list for each size class contains same-size blocks, each the size of the largest element of the size class.
(example : if some size class is defined as {17-32}, the free list for that class consists entirely of blocks of size 32.)
- To allocate a block of some given size:
- Check the appropriate free list.
- If the list is not empty → allocate the first block in the list in its entirety. Free blocks are never split to satisfy allocation requests.
- If the list is empty:
- The allocator requests a fixed-size chunk of additional memory from the OS.
- The allocator divides the chunk into equal-size blocks, and links the blocks together to form the new free list.
- To free a block, the allocator simply inserts the block at the front of the appropriate free list.
- Allocating and freeing blocks are both fast constant-time operations.
- No splitting, no coalescing, the size of an allocated block can be inferred from its address, the list need only be singly linked (allocate and free operations insert and delete blocks at the beginning of the free list) → the only required field in any block is a one-word
succpointer in each free block. → the minimum block size is only one word.
- Simple segregated storage is susceptible to internal and external fragmentation. - Free blocks are never split, and never coalesced.
- With simple segregated storage, the free list for each size class contains same-size blocks, each the size of the largest element of the size class.
- Segregated Fits
- The allocator maintains an array of free lists, where each free list contains potentially different-size blocks whose sizes are members of the size class.
- To allocate a block:
- Determine the size class of the request, and do a first-fit search of the appropriate free list for a block that fits.
- If found one → (optionally) split it, insert the fragment in the appropriate free list.
- If failed to find one → search the free list for the next larger size class. Repeat until we find a block that fits.
- If none of the free lists yields a block that fits → request additional heap memory from the OS, allocate the block out of this new heap memory, and place the remainder in the appropriate size class.
- To free a block, coalesce and place the result on the appropriate free list.
- The segregated fits is fast - Search times are reduced because searches are limited to particular parts of the heap.
- The segregated fits is memory efficient - A simple first-fit search of a segregated free list approximates a best-fit search of the entire heap.
- Buddy Systems
- A buddy system is a special case of segregated fits where each size class is a power of 2.
- Given a heap of words, we maintain a separate free list for each block size , where . (Originally, there is one free block of size words.)
- Requested block sizes are rounded up to the nearest power of 2.
- To allocate a block of size :
- Find the first available block of size , such that .
- If j = k, we are done.
- Otherwise, we recursively split the block in half until j = k. As we perform splitting, each remaining half (buddy) is placed on the appropriate free list.
- To free a block of size , we continue coalescing with the free buddies. When we encounter an allocated buddy, we stop the coalescing.
- Given the address and size of a block, it’s easy to compute the address of its buddy.
(Example : a block of size 32 bytes with address xxx…x00000 has its buddy at address xxx…x10000.)
- The buddy system allocator is fast in searching and coalescing.
- The power-of-2 requirement on the block size can cause significant internal fragmentation.
- Simple Segregated Storage
9.10 Garbage Collection
9.10 Garbage Collection
Garbage Collector Basics
A garbage collector is a dynamic storage allocator that automatically frees allocated blocks that are no longer needed by the program (garbage).
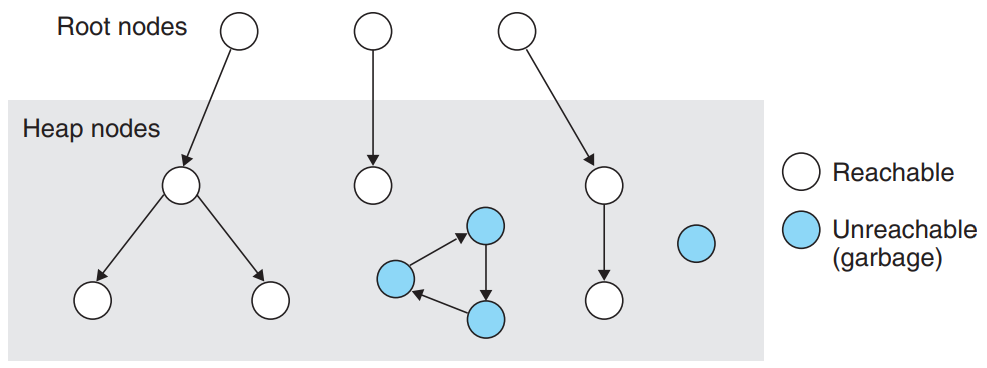
- A garbage collector views memory as a directed reachability graph:
- The nodes of the graph are partitioned into a set of root nodes and a set of heap nodes.
- Each heap node corresponds to an allocated block in the heap.
- Root nodes correspond to locations not in the heap that contain pointers into the heap.
(examples: registers, variables on the stack, or global variables in the read/write data area)
- A directed edge p→q means that some location in block p points to some location in block q.
- The garbage collector maintains some representation of the reachability graph and periodically reclaim the unreachable nodes (=garbage) by freeing them.
- Conservative garbage collectors : collectors which can correctly identify each reachable block as reachable, while may incorrectly identify some unreachable nodes as reachable.
(example : Collectors for languages like C and C++)
- Collectors can provide their service on demand, or they can run as separate threads in parallel with the application.
- A garbage collector views memory as a directed reachability graph:
Mark&Sweep Garbage Collectors
A Mark&Sweep garbage collector consists two phases:
- Mark phase marks all reachable and allocated descendants of the root nodes.
- Sweep phase frees each unmarked allocated block.
typedef void* ptr; void mark(ptr p){ if ((b = isPtr(p)) == NULL) return; if(blockMarked(b)) return; markBlock(b); len = length(b); for (i=0; i < len; i++) mark(b[i]); return; } void sweep(ptr b, ptr end) { while (b < end) /* Iterate over each block in the heap */ if (blockMarked(b)) unmarkBlock(b); else if (blockAllocated(b)) free(b); b = nextBlock(b); } return; }ptr isPtr(ptr p): Ifppoints to some word in an allocated block, it returns a pointerbto the beginning of that block. Returns NULL otherwise.
- The mark phase calls
markonce for each root node. The sweep phase is a single call to thesweep.
Conservative Mark&Sweep for C Programs
The C language poses some challenges for the implementation of the
isPtr:- C doesn’t tag memory locations with any type information. - There is no obvious way for
isPtrto determine if its input parameterpis a pointer or not.
- There is no obvious way for
isPtrto determine whetherppoints to the payload of an allocated block.
Solution : Maintain the set of allocated blocks as a balanced binary tree that maintains the invariant that all blocks in the left subtree are located at smaller addresses and all blocks in the right subtree are located in larger addresses.
- This requires two additional fields (
left&right) in the header of each allocated block. Each field points to the header of some allocated block.
isPtr(ptr p)uses the tree to perform a binary search of the allocated blocks. It relies on the size field in the block header to determine ifpfalls within the extent of the block.
- This solution is guaranteed to mark all of the nodes that are reachable from the roots.
- This solution is conservative - it may incorrectly mark blocks that are actually unreachable, and thus it may fail to free some garbage. → can result in unnecessary external fragmentation.
- scalars like
ints orfloats can masquerade as pointers.
- example : when some reachable allocated block contain an
intin its payload whose value corresponds to an address in the payload of some other allocated block b, the allocator must conservatively mark block b as reachable.
- scalars like
- C doesn’t tag memory locations with any type information. - There is no obvious way for
9.11 Common Memory-Related Bugs in C Programs
9.11 Common Memory-Related Bugs in C Programs
- Dereferencing Bad Pointers
- If we attempt to dereference a pointer into one of large holes in the VAS, OS will terminate the process with a segmentation exception.
- If we attempt to write to one of read-only areas, OS will terminate the process with a protection exception.
scanf("%d", val) /* Buggy Code */ scanf("%d", &val) /* You should pass scanf the address of the variable. */
- Reading Uninitialized Memory
- While bss memory locations are always initialized to zeros by the loader, this is not true for heap memory.
/* Return y = Ax */ int *matvec(int **A, int *x, int n){ int i, j; int *y = (int *)Malloc(n * sizeof(int)); for (i = 0; i < n; i++) for (j = 0; j < n; j++) y[i] += A[i][j] * x[j]; /* Wrong part - y[i] is not initialized to zero! */ return y; }→ Explicitly zero
y[i]or usecalloc.
- Allowing Stack Buffer Overflows
void bufoverflow(){ char buf[64]; gets(buf); /* Here is the stack buffer overflow bug */ return; }getscopies an arbitrary-length string to the buffer. → Usefgets, which limits the size of the input string.
- Assuming That Pointers and the Objects They Point to Are the Same Size
/* Create an nxm array */ int **makeArray1(int n, int m){ int i; int **A = (int **)Malloc(n * sizeof(int)); /* Wrong part - should be sizeof(int*) */ for (i = 0; i < n; i++) A[i] = (int *)Malloc(m * sizeof(int)); return A; }If we run this code on the Core i7, where a pointer is larger than an
int, the loop will write past the end of theAarray. One of these words will likely be the boundary-tag footer of the allocated block → The error can occur when the coalescing code in the allocator fails for no apparent reason.
- Making Off-by-One Errors
/* Create an nxm array */ int **makeArray2(int n, int m){ int i; int **A = (int **)Malloc(n * sizeof(int *)); for (i = 0; i <= n; i++) /* Wrong part - should be i < n */ A[i] = (int *)Malloc(m * sizeof(int)); return A; }This code will try to initialize n + 1 of its elements, overwriting some memory that follows the
Aarray.
- Referencing a Pointer Instead of the Object It Points To
int *binheapDelete(int **binheap, int *size){ int *packet = binheap[0]; binheap[0] = binheap[*size - 1]; *size--; /* Wrong part - should be (*size)-- */ heapify(binheap, *size, 0); return(packet); }The unary
--and*operators have the same precedence and associate from right to left →*size--;actually decrements the pointer itself instead of the integer value that it points to. → Use parentheses!
- Misunderstanding Pointer Arithmetic
int *search(int *p, int val){ while (*p && *p != val) p += sizeof(int); /* Wrong part - should be p++ */ return p; }The arithmetic operations on pointers are performed in units that are the size of the objects they point to. → This function incorrectly scans every fourth integer in the array.
- Referencing Nonexistent Variables
int *stackref(){ int val; return &val; }This functions returns a pointer to a local variable on the stack, and then pops its stack frame. → Although the pointer still points to a valid memory address, it no longer points to a valid variable.
- Referencing Data in Free Heap Blocks
int *heapref(int n, int m){ int i; int *x, *y; x = (int *)Malloc(n * sizeof(int)); // Other calls to malloc and free go here free(x); y = (int *)Malloc(m * sizeof(int)); for (i = 0; i < m; i++) y[i] = x[i]++; /* Wrong part - x[i] is a word in a free block. */ return y; {
- Introducing Memory Leaks
void leak(int n){ int *x = (int *)Malloc(n * sizeof(int)); return; /* Wrong part - x is garbage at this point */ }
Leave a comment