CS:APP Chapter 8 Summary ⚠
Recently, I’ve been studying CS:APP - I’m posting my own summary of chapter 8 that I wrote up using Notion.
8.1 Exceptions
8.1 Exceptions
Exception & Exception handler
An exception is an abrupt change in the control flow in response to some change in the processor’s state.
The state is encoded in various bits and signals inside the processor.
The event is the change in state.
Processor detects that the event has occurred → Processor makes an indirect procedure call through an exception table to an OS subroutine (exception handler).
When the exception handler finishes processing, one of 3 things happens depending on the type of event :
- The handler returns control to the current instruction, the instruction that was executing when the event occurred.
- The handler returns control to the next instruction, the instruction that would have executed next had not the exception not occurred.
- The handler aborts the interrupted program.
Exception Handling
Each type of possible exception in a system is assigned a unique nonnegative integer exception number.
The exception table’s entry k contains the address of the handler for exception k.
- Exception handling

- The processor detects that an event has occurred
- The processor determines the corresponding exception number k.
- The processor triggers the exception by making an indirect procedure call to the corresponding handler through entry k of the exception table.
The starting address of exception table is contained a special CPU register called the exception table base register.
- Exception’s differences to a procedure call
- For both exception & procedure call, the processor pushes a return address on the stack before jumping to the handler. However, the exception’s return address is either the current instruction or the next instruction depending on the class of exception.
- The processor also pushes some additional processor state onto the stack that will be necessary to restart the interrupted program.
- When control is being transferred from a user program to the kernel, the return address & processor states are pushed onto the kernel’s stack.
- Exception handlers run in kernel mode - they have complete access to all system resources.
Classes of Exceptions
- Interrupts
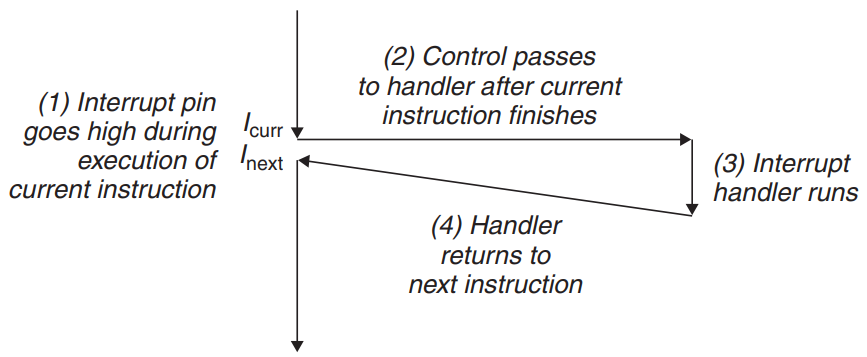
- Interrupts occur asynchronously as a result of signals from I/O devices that are external to the processor. (example : network adapters, disk controllers, & timer chips)
- I/O devices interrupts by signaling a pin on the processor chip and placing the exception number onto the system bus.
- After the current instruction finishes executing, the processor notices that the interrupt pin has gone high.
- The processor reads the exception number from the system bus, and then calls the appropriate interrupt handler.
- When the handler returns, it returns control to the next instruction. - The program continues executing as if the interrupt had never happened.
- Traps & System Calls

- Traps are intentional exceptions that occur as a result of executing an instruction.
- Traps return control to the next instruction.
- The most important use of traps is to provide a procedure-like interface between user programs and the kernel, known as a system call.
- Processors provide a
syscall ninstruction that user programs can execute when they want to request service n. → Controlled access to kernel services is available.
- Executing the
syscallinstruction causes a trap to an exception handler that decodes the argument and calls the appropriate kernel routine.
- A system call runs in kernel mode - it can execute privileged instructions & access a stack defined in the kernel.
- Faults
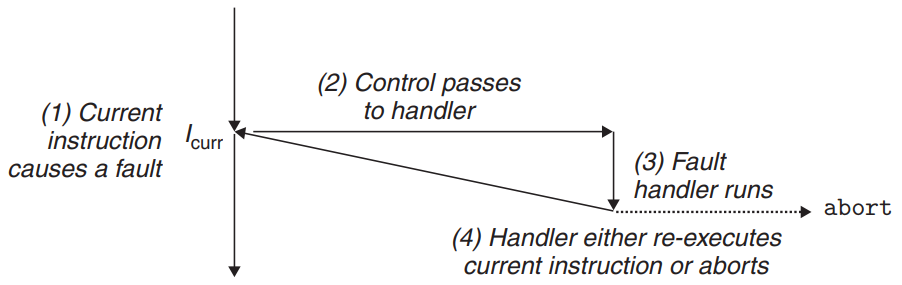
- Faults result from error conditions that a handler might be able to correct.
- If the handler is able to correct the error condition, it returns control to the faulting instruction. Otherwise, the handler returns to an
abortroutine in the kernel that terminates the application program.
- Example : Page fault exception
- Aborts
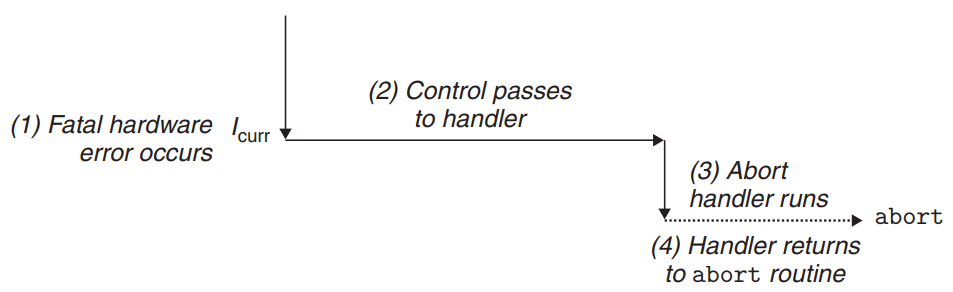
- Aborts result from unrecoverable fatal errors, typically hardware errors.
- Abort handlers never return control to the application program - The handler returns control to an
abortroutine that terminates the application program.
- Interrupts
Exceptions in Linux/x86-64 Systems
There are up to 256 different exceptions defined for x86-64 systems - Numbers from 0 to 31 correspond to exceptions defined by the Intel architects, and numbers 32 to 255 correspond to interrupts & traps defined by OS.
- Linux/x86-64 Faults and Aborts
- Divde error : occurs when an application attempts to divide by 0 or when the result of a divide instruction is too big for the destination operand. → Abort
- General protection fault : occurs for many reasons, usually because a program references an undefined area of VM or because the program attempts to write to a read-only text segment. → Abort
- Page fault : occurs when an instruction references a virtual address whose corresponding page is not resident in memory and must be retrieved from disk. → The handler maps the appropriate page of VM on disk into a page of physical memory, and then restarts the faulting instruction. → Fault
- Machine check : occurs as a result of a fatal hardware error that is detected during the execution of the faulting instruction. → Abort
- Linux/x86-64 System Calls
Each system call has a unique integer number that corresponds to an offset in a jump table in the kernel. (This jump table ≠ Exception table)
C programs can invoke any system call directly by using the
syscallfunction, but C standard library provides a wrapper functions for most system calls.All arguments to Linux system calls are passed through general-purpose registers rather than the stack. -
%raxcontains the syscall number,%rdi,%rsi,%rdx,%r10,%r8, and%r9contains up to six arguments. On return from the system call,%rcxandr11are destroyed, and%raxcontains the return value. A negative return value (-4095 ~ -1) indicates an error corresponding to negativeerrno.
- Linux/x86-64 Faults and Aborts
8.2 Processes
8.2 Processes
Process is an instance of a program in execution.
Key abstractions that a process provides to the application :
- An independent logical control flow that provides the illusion that our program has exclusive use of the processor.
- A private address space that provides the illusion that our program has exclusive use of the memory system.
Logical Control Flow
The sequence of PC values is known as a logical control flow.
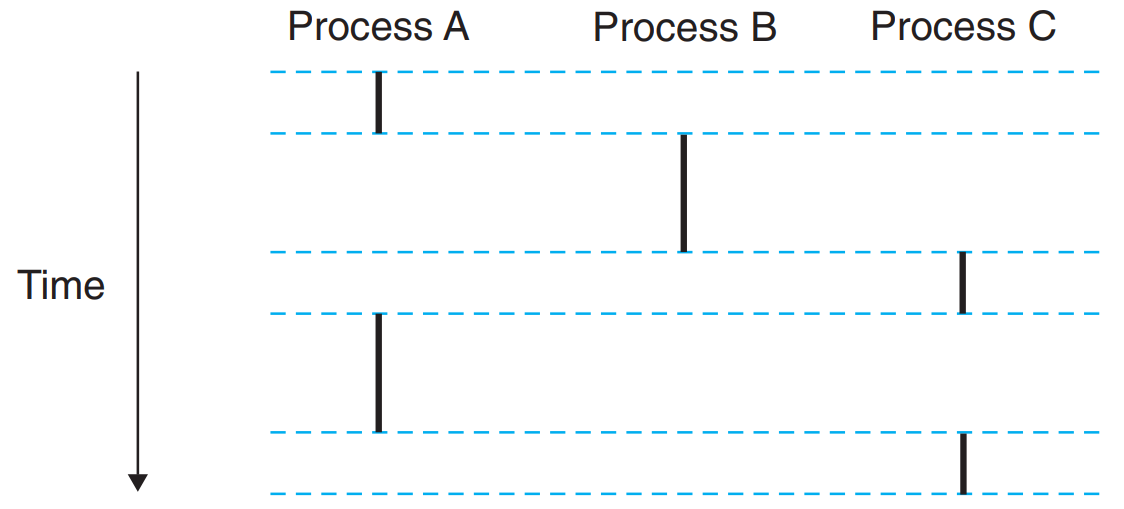
Processes take turns using the processor - Each process executes a portion of its flow and then is preempted (temporarily suspended) while other processes take their turns.
Logical flows take many different forms in computer systems - Exception handlers, processes, signal handlers, threads, and Java processes.
Flows X and Y are concurrent with respect to each other ↔ X begins after Y begins and before Y finishes, or Y begins after X begins and before X finishes. (example : process A & B in the figure are concurrent.)
Parallel flows refers to flows running concurrently on different processor cores or computers.
Private Address Space
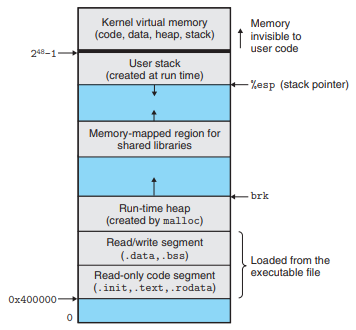
On a machine with n-bit addresses, the address space is the set of possible addresses, 0, 1, ... , .
A process provides each program with its own private address space - a byte of memory associated with a particular address in the space can’t be read or written by any other process in general.
Each address space has the same general organization.
User and Kernel Modes
In typical processor, there is a mode bit in some control register that characterizes the privileges that the process currently enjoys.
- Kernel mode
- When the mode bit is set, the process is running in kernel mode.
- The process in kernel mode can execute any instruction in the instruction set & access any memory location in the system.
- User mode
- When the mode bit is not set, the process is running in user mode.
- The process in user mode is not allowed to execute privileged instructions, change the mode bit, initiate an I/O operation, or reference code or data in the kernel area. Any such attempt results in a fatal protection fault.
- User programs must access kernel code & data via the system call interface.
- The only way for the process to change from user mode to kernel mode is via an exception such as interrupt, a fault, or a trapping system call. - When the handler is called, the handler runs in the kernel mode. When it returns to the application code, the processor’s mode changes back to user mode.
- Linux provides
/procfilesystem, that allows user mode processes to access the contents of kernel data structures. The/procfilesystem exports the contents of many kernel data structures as a text files that can be read by user programs.
- Kernel mode
Context Switches
- Context
- The context is the state that the kernel needs to restart a preempted process.
- The context consists of the values of the objects such as :
- General-purpose registers
- The floating-point registers
- The PC
- User’s stack
- Status registers
- Kernel’s stack
- A page table that characterizes the address space
- A process table that contains information about the current process
- A file table that contains information about the files that the process has opened.
- Context Switch
- The kernel can decide to preempt the current process and restart a previously preempted process → Scheduling
- The kernel transfers control to the new process using a context switch :
- Saves the context of the current process
- Restores the saved context of some previously preempted process
- Passes control to this newly restored process
- A context switch can occur if the system call blocks because it is waiting for some event to occur.
- A context switch can occur as a result of an interrupt. (example : Periodic timer interrupts)
- Example of Context Switch
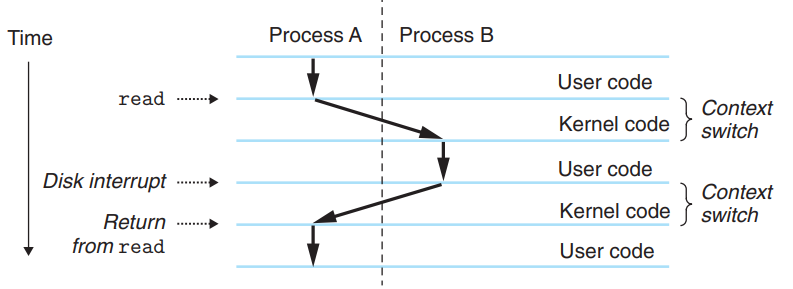
- Process A traps to the kernel by executing a
readsystem call.
- The DMA transfer will take a relatively long time → The kernel performs a context switch from process A to B.
- During the context switching, the kernel is executing instructions in kernel mode on behalf of process A. Then at some point it begins executing instructions on behalf of process B still in kernel mode.
- After the switch, the kernel is executing instructions in user mode on behalf of process B.
- The disk sends an interrupt to signal that data have been transferred from disk to memory. → The kernel performs a context switch from process B to A.
- Process A traps to the kernel by executing a
- Context
8.3 System Call Error Handling
8.3 System Call Error Handling
Unix system-level functions return -1 on error, and set the global integer variable errno to indicate what went wrong.
- Example of checking error when calling
forkfunction :
if ((pid = fork()) < 0) {
fprintf(stderr, "fork error: %s\n", strerror(errno));
exit(0);
}strerror returns a text string that describes the error associated with a value of errno.
We can define error-reporting function to simplify the code :
void unix_error(char *msg){
fprintf(stderr, "%s: %s\n", msg, strerror(errno));
exit(0);
}We can simplify the code further by using error-handling wrappers :
pid_t Fork(void){
pid_t pid;
if ((pid = fork()) < 0)
unix_error("Fork error");
return pid;
}
pid = Fork();8.4 Process Control
8.4 Process Control
Obtaining Process IDs -
getpid,getppid#include <sys/types.h> #include <unistd.h> pid_t getpid(void); pid_t getppid(void);Each process has a unique positive process ID (PID).
getpidreturns the PID of the calling process.getppidreturns the PID of its parent.Type
pid_tis defined intypes.has an int.
Creating and Terminating Processes -
fork,exit- States of process
A process can be in one of three states :
- Running : The process is either executing on the CPU or waiting to be executed and will eventually be scheduled by kernel.
- Stopped : The execution of the process is suspended & won’t be scheduled.
- Terminated : The process is stopped permanently. A process becomes terminated for one of three reasons :
- receiving a signal whose default action is to terminate the process
- returning from the main routine
- calling the
exitfunction
exit- Terminating Process#include <stdlib.h> void exit(int status);exitterminates the process with an exit status ofstatus.
fork- Creating ProcessA parent process creates a new running child process by calling the
fork.#include <sys/types.h> #include <unistd.h> pid_t fork(void);- The child gets an identical copy of parent’s user-level virtual address space including the code & data segments, heap, shared libraries, and user stack.
- The child gets an identical copies of the parent’s open file descriptors - the child can read and write any files that were open in the parent when it called
fork.
- The child and parent have different PIDs.
forkis called once but it returns twice.- In the parent,
forkreturns the PID of the child.
- In the child,
forkreturns a value of 0.
- In the parent,
- Example code of
forkint main(){ pid_t pid; int x = 1; pid = Fork(); if (pid == 0) { /* Child */ printf("child : x=%d\n", ++x); exit(0); } /* Parent */ printf("parent : x=%d\n", --x); exit(0); }Result :
parent : x = 0child : x = 2- The instructions in the parent & child’s logical control flows can be interleaved by the kernel in an arbitrary way → We can never make assumptions about the interleaving of the instructions in different processes.
- At the point immediately after the
forkreturned in each process, the address space of each process is identical.
- Since the parent and the child are separate processes, they each have their own private address spaces → Any subsequent changes the processes make to
xare private and are not reflected in the memory of each other.
- Both parent and child print their output on the screen - The child inherits all of the parent’s open files.
- We can use process graph to understand the behavior of the processes :
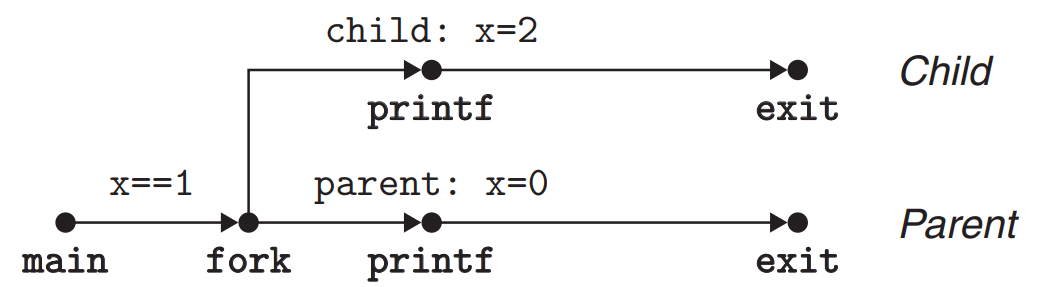
- Any topological sort of the vertices in the process graph represents a feasible total ordering of the statements in the program.
- States of process
Reaping Child Processes -
waitpid,wait- Reaping Child Processes
- When a process terminates, the process is not removed from the system immediately (zombie) - the process is kept around in a terminated state until it is reaped by its parent.
- The parent reaps the terminated child → the kernel passes the child’s exit status to the parent & discards the terminated process.
- When a parent process terminates, the kernel arranges for the
initprocess to become the adopted parent for any orphaned children.initprocess is created by the kernel during system start-up, never terminates.
initprocess is the ancestor of every process.
initprocess has a PID of 1.
- If a parent process terminates without reaping its zombie children,
initprocess reaps them.
- Long-running programs (servers or shells) should always reap their zombie children - or zombies will consume system memory resources.
waitpid- Waiting for children process to terminate or stop, then Reaping it#include <sys/types.h> #include <sys/wait.h> pid_t waitpid(pid_t pid, int *statusp, int options);- When
options= 0,waitpidsuspends execution of the calling process until a child process in its wait set terminates. If a process in the wait set has already terminated, thenwaitpidreturns immediately.
- When
options= 0,waitpidreturns PID of the terminated child that causewaitpidto return. Then, the terminate child has been reaped & the kernel removes the process.
- Determining the Members of the Wait Set - determined by
pidargumentpid> 0 → the wait set is a single child process whose PID ispid.
pid= -1 → the wait set consists of all of the child processes.
- Modifying the Default Behavior - setting
optionsto combinations ofWNOHANG,WUNTRACED,WCONTINUEDWNOHANG: Return immediately with a return value of 0 if none of the child processes in the wait set has terminated yet.
WUNTRACED: Suspend execution of the calling process until a process in the wait set becomes either terminated or stopped. Return the PID of the terminated or stopped child.
WCONTINUED: Suspend execution of the calling process until a running process in the wait set is termianted or until a stopped process in the wait set has been resumed by the receipt of aSIGCONTsignal.
- Can combine options -
WNOHANG | WUNTRACED: Return immediately with a return value of 0 if none of the children in the wait set has stopped or terminated, or with a return value of PID of one of the stopped or terminated children.
- Checking the Exit Status of a Reaped Child
- If
stautspis not NULL,waitpidencodes status information about the child instatus(=*statusp).
wait.hdefines macros for interpreting thestatusargument :WIFEXITED(status): Returns true if the children terminated via a call toexitor a return.
WEXITSTATUS(status): Returns the exit status of a normally terminated child. Only defined ifWIFEXITEDreturned true.
WIFSIGNALED(status): Returns true if the child process terminated because of a signal that wasn’t caught.
WTERMSIG(status): Returns the number of the signal that caused the process to terminate. Only defined ifWIFSIGNALEDreturned true.
WIFSTOPPED(status): Returns true if the child that caused the return is currently stopped.
WSTOPSIG(status): Returns the number of the signal that caused the child to stop. Only defined ifWIFSTOPPEDreturned true.
WIFCONTINUED(status): Returns true if the child process was restarted by receipt of aSIGCONTsignal.
- If
- If the calling process has no children,
waitpidreturns -1, and setserrnotoECHILD.
- If the
waitpidfunction was interrupted by a signal, it returns -1 and setserrnotoEINTR.
- When
wait- Simpler version ofwaitpid#include <sys/types.h> #include <sys/wait.h> pid_t wait(int *statusp);wait(&status)is equivalent towaitpid(-1, &status, 0).
- Example code : Using
waitpidto reap zombie children in no particular order#include "csapp.h" #define N 2 int main() { int status, i; pid_t pid; /* Parent creates N children */ for (i = 0; i < N; i++) if ((pid = Fork()) == 0) /* Child */ /* Line 11 */ exit(100+i); /* Parent reaps N children in no particular order */ while ((pid = waitpid(-1, &status, 0)) > 0) { /* Line 16 */ if (WIFEXITED(status)) printf("child %d terminated normally with exit status=%d\n", pid, WEXITSTATUS(status)); else printf("child %d terminated abnormally\n", pid); } /* The only normal termination is if there are no more children */ if (errno != ECHILD) unix_error("waitpid error"); exit(0); }- The program reaps its children in no particular order → An example of nondeterministic behavior.
- To eliminate the nondeterminism, store the PIDs of its children in order, then wait for each child in the same order by calling
waitpidwith the appropriate PID in the first argument.- line 11 →
if ((pid[i] = Fork()) == 0)
- line 16 →
while ((retpid = waitpid(pid[i++], &status, 0)) > 0) {
- line 11 →
- Reaping Child Processes
Putting Processes to Sleep -
sleep,pausesleep- Suspending a process for a specified period of time#include <unistd.h> usigned int sleep(unsigned int secs);sleepreturns 0 if the requested time has elapsed.sleepreturns the number of seconds still left to sleep ifsleepreturns prematurely being interrupted by a signal.
pause- Putting the calling function to sleep until a signal is received by the process.#include <unistd.h> int pause(void);pausealways return -1.
Loading & Running Programs -
execveexcve- Loading & Running a new program in the context of the current process#include <unistd.h> int execve(const char *filename, const char *argv[], const char *envp[]);execveloads & runs the executable object filefilenamewith the argument listargvand the environment listenvp.
execvereturns only if there is an error - In normal operation,execvenever returns.
- Argument list
argv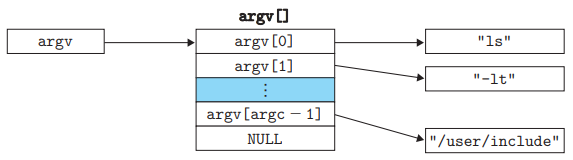
argvpoints to a null-terminated array of pointers, each of which points to an argument string.
argv[0]is the name of the executable object file.
- Environment variable list
envp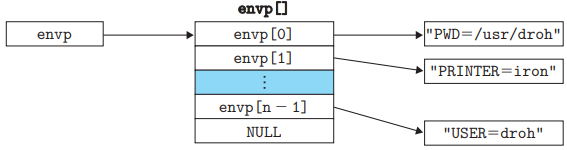
envppoints to a null-terminated array of pointers to environment variable strings, each of which is a name-value pair of the form ‘name = value’.
- Executing
mainafterexecveloadsfilename- After
execveloadsfilename,execvecalls the start-up code that sets up the stack & passes control to the main routine of the new program.
- The main routine has a form
int main(int argc, char **argv, char **envp);, or equivalentlyint main(int argc, char *argv[], char *envp[]);.
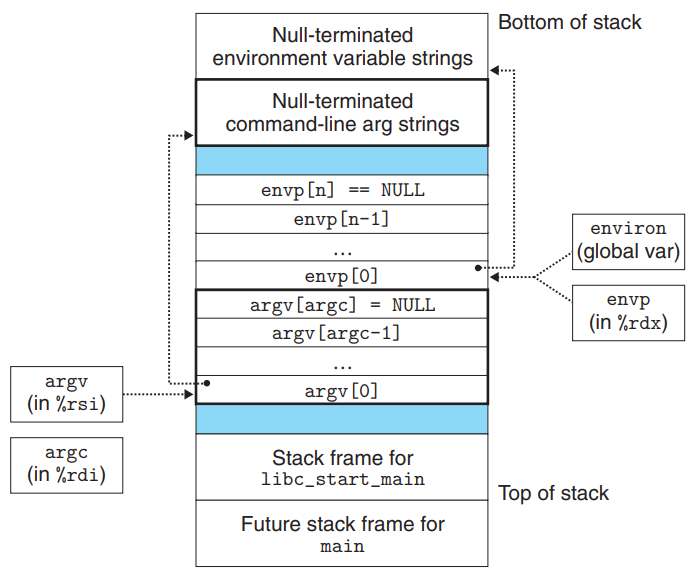
- The organization of user stack when a new program starts (From bottom to top)
- The argument & environment strings are at the bottom of the stack (the highest address).
- Environment array
envp[]. The global variableenvironpoints to the first of these pointers,envp[0].
- Argument array
argv[].
- Stack frame for the system start-up function,
libc_start_main.
- There are 3 arguments to
main, each stored in a register :argcgives the number of non-null pointers in theargv[]array.
argvpoints to the first entry in theargv[]array.
envppoints to the first entry in theenvp[]array.
- After
getenv,setenv,unsetenv- Manipulating the environment array#include <stdlib.h> char *getenv(const char *name); int setenv(const char *name, const char *newvalue, int overwrite); void unsetenv(const char *name);getenvsearches theenvp[]for a string ‘name=value’. If found, it returns a pointer tovalue; otherwise, it returnsNULL.
unsetenvdeletes the string of the form ‘name=oldvalue’.
setenvreplaces oldvalue withnewvalue, only ifoverwriteis nonzero. Ifnamedoesn’t exist,setenvadds ‘name=newvalue’ to the array.
Using
fork&execveto Run ProgramsA shell is an interactive application-level program that runs other programs on behalf of the user. A shell performs a sequence of read/evaluate steps and then terminates :
#include "csapp.h" #define MAXARGS 128 /* Function prototypes */ void eval(char *cmdline); int parseline(char *buf, char **argv); int builtin_command(char **argv); int main(){ char cmdline[MAXLINE]; /* Command line */ while (1) { /* Read */ printf("> "); Fgets(cmdline, MAXLINE, stdin); if (feof(stdin)) exit(0); /* Evaluate */ eval(cmdline); } }- The shell prints a command-line prompt, waits for the user to type a command line on
stdin, and then evaluates the command line.
/* eval - Evaluate a command line */ void eval(char *cmdline){ char *argv[MAXARGS]; /* Argument list execve() */ char buf[MAXLINE]; /* Holds modified command line */ int bg; /* Should the job run in background or foreground? */ pid_t pid; /* Process ID */ strcpy(buf, cmdline); bg = parseline(buf, argv); if (argv[0] == NULL) return; /* Ignore empty lines */ if (!builtin_command(argv)) { if ((pid = Fork()) == 0) { /*Child runs user job */ if (execve(argv[0], argv, environ) < 0) { printf("%s: Command not found.\n", argv[0]); exit(0); } } /* Parent waits for foreground job to terminate */ if (!bg) { int status; if (waitpid(pid, &status, 0) < 0) unix_error("waitfg: waitpid error"); } else printf("%d %s", pid, cmdline); } return; }evalevaluates the command line.
- It first call the
parselinefunction which parses the space-separated command-line arguments and builds theargvvector that will be passed toexecve./* parseline - Parse the command line and build the argv array */ int parseline(char * buf, char **argv){ char *delim; /* Points to first space delimiter */ int argc; /* Number of args */ int bg; /* Background job? */ buf[strlen(buf)-1] = ' '; /* Replace trailing '\n' with space */ while (*buf && (*buf == ' ')) buf++; /* Ignore leading spaces */ /* Build the argv list */ argc = 0; while ((delim = strchr(buf, ' '))) { argv[argc++] = buf; *delim = '\0'; buf = delim + 1; while (*buf && (*buf == ' ')) buf++; /* Ignore spaces */ } argv[argc] = NULL; if(argc == 0) return 1; /* Ignore blank line */ /* Should the job run in the background? */ if ((bg = (*argv[agrc-1] == '&')) != 0) argv[--argc] = NULL; return bg; }- The first argument is assumed to be either the name of a built-in shell command, or an executable object file that will be loaded & run in the context of a new child process.
- If the last argument is an ‘&’ character, then
parselinereturns 1, indicating that the program should be executed in the background (the shell doesn’t wait for it to complete).
- Otherwise, it returns 0, indicating that the program should be run in the foreground (the shell waits for it to complete).
- After parsing, the
evalcallsbuiltin_commandwhich checks whether the first command-line argument is a built-in shell command./* If first arg is a builtin command, run it and return true */ int builtin_command(char **argv){ if(!strcmp(argv[0], "quit")) exit(0); /* quit command */ if(!strcmp(argv[0], "&")) return 1; /* Ignore singleton & */ return 0; /* Not a builtin command */ }- If first argument is a built-in command,
builtin_commandimmediately interprets the command and returns 1.
- Otherwise, it returns 0.
- In this example, the shell has just one built-in command,
quit.
- If first argument is a built-in command,
- If
builtin_commandreturns 0, the shell creates a child process and executes the requested program inside the child.
- If asked to run in the background, the shell then returns to the top of the loop and waits for the next command line.
- Otherwise, the shell uses the
waitpidfunction to wait for the job to terminate.
- This shell is flawed - it doesn’t reap any of its background children. Correcting this flaw requires the use of signals.
- The shell prints a command-line prompt, waits for the user to type a command line on
8.5 Signals
8.5 Signals
A signal is a small message that notifies a process that an event of some type has occurred in the system.
Low-level hardware exceptions are processed by the kernel’s exception handlers, and wouldn’t be visible to user processes. → Signals provide a mechanism for exposing the occurrence of such exceptions to user processes.
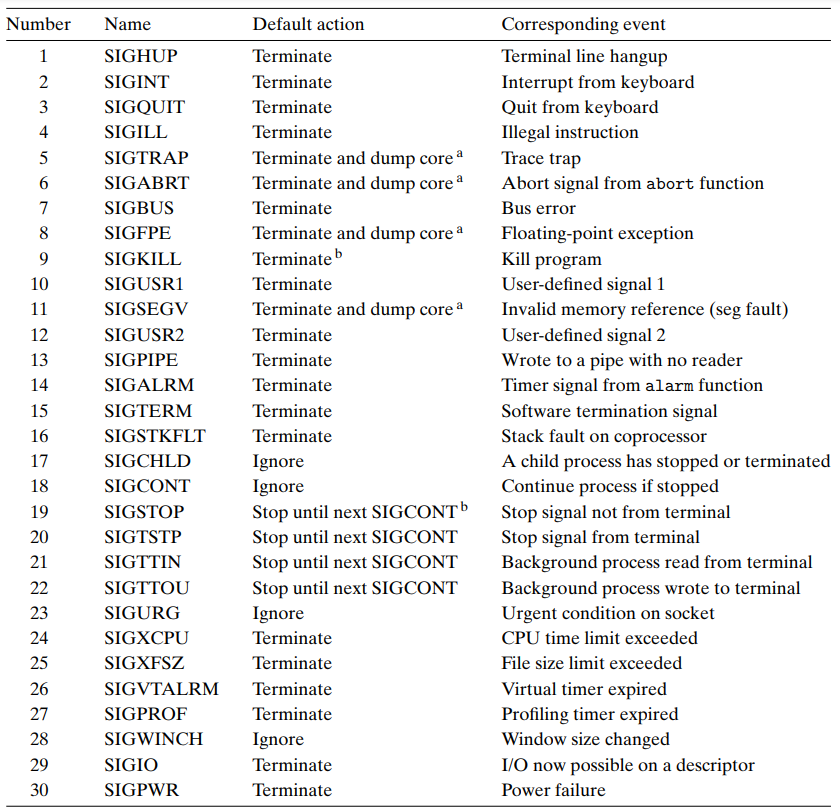
Signal Terminology
- Transfer of a signal
The transfer of a signal occurs in two distinct steps:
- Sending (Delivering) a signal
The kernel sends (delivers) a signal to a destination process by updating some state in the context of the destination process.
The signal is delivered for one of two reasons:
- The kernel has detected a system event. (example : divide-by-zero error or the termination of a child process)
- A process has invoked the
killfunction to explicitly request the kernel to send a signal to the destination process.
- Receiving a signal
A destination process receives a signal when it is forced by the kernel to react to the delivery of the signal.
The process can react in three different ways:
- The process can ignore the signal.
- The process can terminate.
- The process can catch the signal by executing a user-level function called a signal handler. - The signal handler returns to next instruction after handling the signal.
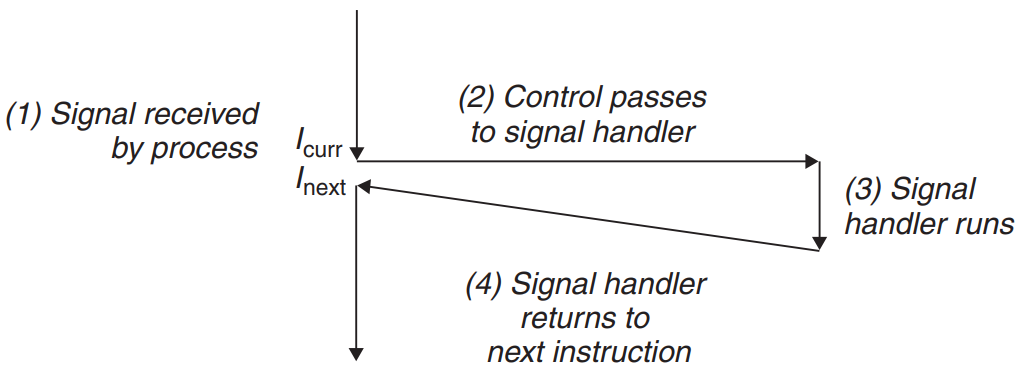
- Sending (Delivering) a signal
- A pending signal
- A pending signal is a signal that has been sent but not yet received.
- If a process has a pending signal of type k, then any subsequent signals of type k sent to that process are not queued - they are simply discarded.
- A process can block the receipt of certain signals - When a signal is blocked, it can be delivered, but the resulting pending signal won’t be received until the process unblocks the signal.
- For each process, the kernel maintains the set of pending signals in the
pendingbit vector, and the set of blocked signals in theblockedbit vector.The kernel sets bit k in
pendingwhen a signal of type k is delivered, and clears bit k inpendingwhenever a signal of type k is received.
- Transfer of a signal
Sending Signals -
getpgrp,setpgid,/bin/kill,kill,alarm- Process Groups -
getpgrp,setpgidEvery process belongs to exactly one process group, which is identified by a positive integer process group ID.
#include <unistd.h> pid_t getpgrp(void); int setpgid(pid_t pid, pid_t pgid);getpgrpreturns the process group ID for the current process.setpgidchanges the process group of processpidtopgid. Ifpidis zero, the PID of the current process is used. Ifpgidis zero,pidis used for the process group ID.(example : if process 15213 is the calling process,
setpgid(0, 0);creates a new process group whose process group ID is 15213, and adds process 15213 to this new group.)
- Sending Signals with the
/bin/killProgram/bin/killprogram sends an arbitrary signal to another process.(example :
linux> /bin/kill -9 15213→ sends signal 9 (SIGKILL) to process 15213.)A negative PID causes the signal to be sent to every process in process group PID.
(example :
linux> /bin/kill -9 -15213→ sends signal 9 (SIGKILL) to every process in processs group 15213.)
- Sending Signals from the Keyboard
- A job is the abstraction of the processes that are created as a result of evaluating a single command line.
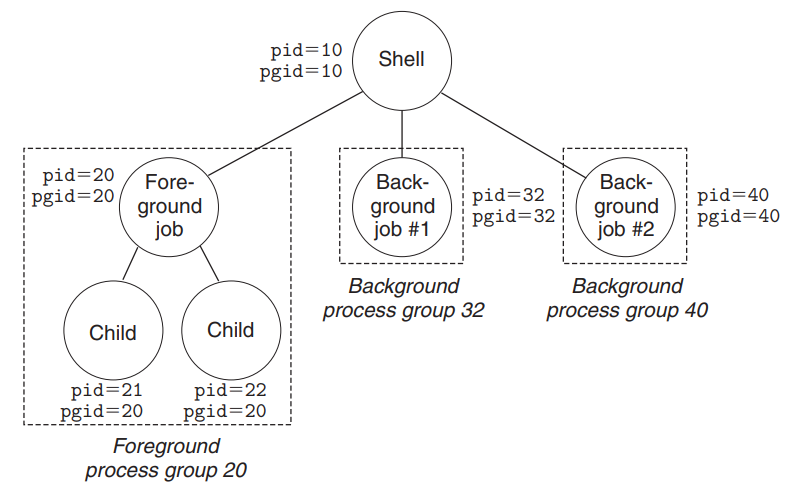
- At any point in time, there is at most one foreground job and zero or more background jobs.
- The shell creates a separate process group for each job. - The process group ID is taken from one of the parent processes in the job.
- Typing Ctrl + C causes the kernel to send a
SIGINTsignal to every process in the foreground process group. In the default case, this signal terminates the foreground job.
- Typing Ctrl + Z causes the kernel to send a
SIGTSTPsignal to every process in the foreground process group. In the default case, this signal stops (suspends) the foreground job.
- Sending Signals with the
killfunction -kill#include <sys/types.h> #include <signal.h> int kill(pid_t pid, int sig);Processes send signals to other processes by calling the
killfunction.pid> 0 →killsends signalsigto processpid.
pid= 0 →killsends signalsigto every process in the process group of the calling process, including the calling process itself.
pid< 0 →killsends signalsigto every process in process group|pid|.
- Example Code : Using
killto send aSIGKILLto a child
#include "csapp.h" int main(){ pid_t pid; /* Child sleeps until SIGKILL signal received, then dies */ if ((pid == FOrk()) == 0) { Pause(); /* Wait for a signal to arrive */ printf("Control should never reach here!\n"); exit(0); } /* Parent sends a SIGKILL signal to a child */ Kill(pid, SIGKILL); exit(0); }
- Sending Signals with the
alarmFunction -alarm#include <unistd.h> unsigned int alarm(unsigned int secs);alarmarranges for the kernel to send aSIGALRMsignal to the calling process insecsseconds.secs= 0 → no new alarm is scheduled.
- The call to
alarmcancels any pending alarms and returns the number of seconds remaining until any pending alarm was due to be delivered, or 0 if there were no pending alarms.
- Process Groups -
Receiving Signals -
signal- Receiving Signals
When the kernel switches a process p from kernel mode to user mode, it checks the set of unblocked pending signals (
pending & ~blocked) for p.If the set is empty, The kernel passes control to the next instruction in the logical control flow of p.
If the set is nonempty:
- The kernel chooses some signal k in the set & forces p to receive signal k.
- The receipt of the signal triggers some action by the process.
- After the action, control passes back to the next instruction in the logical control flow of p.
- Default Action for the Signal
Each signal type has a predefined default action, which is one of the following:
- The process terminates
- The process terminates and dumps core. (= writing an image of the code & data memory segments to disk.)
- The process stops(suspends) until restarted by a
SIGCONTsignal.
- The process ignores the signal.
- Modifying the Default Action for the Signal -
signal#include <signal.h> typedef void (*sighandler_t)(int); sighandler_t signal(int signum, sighandler_t handler);The
signalcan change the action associated with a signalsignumin one of three ways:handerisSIG_IGN→ signals of typesignumare ignored.
handlerisSIG_DFL→ the action for signals of typesignumreverts to the default action.
handleris the address of a user-defined function (signal handler) → Signal handler will be called whenever the process receives a signal of typesignum.When a process catches a signal of type k, the handler is invoked with a single integer argument set to k.
- Example Code : Using a signal handler to catch a
SIGINTsignal.#include "csapp.h" void sigint_handler(int sig){ /* SIGINT handler */ printf("Caught SIGINT!\n"); exit(0); } int main(){ /* Install the SIGINT handler */ if (signal(SIGINT, sigint_handler) == SIG_ERR) unix_error("signal error"); pause(); /* Wait for the receipt of a signal */ return 0; }SIGINTis sent whenever the user types Ctrl+C at the keyboard. The default action forSIGINTis to terminate the process. We modify the default behavior to catch the signal, print a message, and then terminate the process.
- Interrupting Signal Handlers
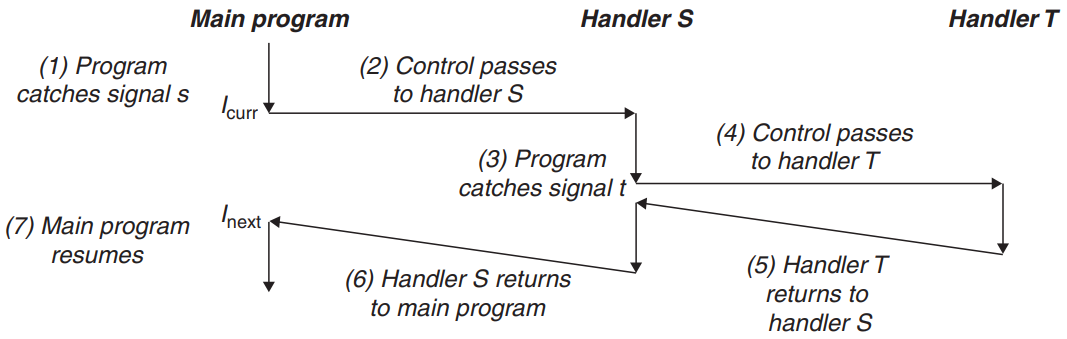
Signal handlers can be interrupted by other handlers.
- Receiving Signals
Blocking & Unblocking Signals -
sigprocmaskLinux provides implicit and explicit mechanisms for blocking signals:
- Implicit Blocking Mechanism
By default, the kernel block any pending signals of the type currently being processed by a handler.
- Explicit Blocking Mechanism
Applications can explicitly block & unblock selected signals using the
sigprocmaskand its helpers.#include <signal.h> int sigprocmask(int how, const sigset_t *set, sigset_t *oldset); int sigemptyset(sigset_t *set); int sigfillset(sigset_t *set); int sigaddset(sigset_t *set, int signum); int sigdelset(sigset_t *set, int signum); int sigismember(const sigset_t *set, int signum);sigprocmaskchanges the set of currently blocked signals (Theblockedbit vector). The specific behavior depends onhow:SIG_BLOCK: Add the signals insettoblocked(blocked = blocked | set).
SIG_UNBLOCK: Remove the signals insetfromblocked(blocked = blocked & ~set).
SIG_SETMASK:blocked = set
If
oldsetis non-NULL, the previous value of theblockedbit vector is stored inoldset.
sigemptysetinitializessetto the empty set.
sigfillsetadds every signal toset.
sigaddsetaddssignumtoset.
sigdelsetdeletessignumfromset.
sigismemberreturns 1 ifsignumis a member ofset, and 0 if not.
- Example Code : Temporary blocking a signal
sigset_t mask, prev_mask; Sigemptyset(&mask); Sigaddset(&mask, SIGINT); /* Block SIGINT and save previous blocked set */ Sigprocmask(SIG_BLOCK, &mask, &prev_mask); // Code region that will not be interrupted by SIGINT /* Restore previous blocked set, unblocking SIGINT */ Sigprocmask(SIG_SETMASK, &prev_mask, NULL);
- Implicit Blocking Mechanism
Writing Signal Handlers : Safe Signal Handling
Signal handlers can run concurrently with the main program. If a handler and the main program access the same global data structure concurrently, the results can be unpredictable.
⇒ We need conservative guidelines for writing handlers that are safe to run concurrently.
- Keep handlers as simple as possible.
For example, define the handler to simply set a global flag and return immediately. Then, let all processing associated with the receipt of the signal is performed by the main program, which periodically checks the flag.
- Call only async-signal-safe functions in your handlers.
A function that is async-signal-safe can be safely called from a signal handler, either because it is reentrant (e.g., accesses only local variables), or because it can’t be interrupted by a signal handler.
In page 803, Figure 8.33 lists the system-level functions that Linux guarantees to be safe.
SIO package are some safe functions developed by CSAPP, that can be used to print simple messages from signal handlers.
#include "csapp.h" ssize_t sio_puts(char s[]){ /* Put string */ return write(STDOUT_FILENO, s, sio_strlen(s)); } ssize_t sio_putl(long v){ /* Put long */ char s[128]; sio_ltoa(v, s, 10); return sio_puts(s); } void sio_error(char s[]){ /* Put error message and exit */ sio_puts(s); _exit(1); /* Safe variant of exit */ }
- Save and restore
errno.Many Linux async-signal-safe functions set
errnowhen they return with an error. → Calling such functions inside a handler might interfere with other parts of the program that rely onerrno.⇒ Save
errnoto a local variable on entry to the handler and restore it before the handler returns.This is only necessary if the handler returns. Not necessary if the handler terminates by calling
_exit.
- Protect accesses to shared global data structures by blocking all signals.
A handler shares a global data structure with the main program or with other handlers → Handlers & main program should temporarily block all signals while accessing that data structure.
If instruction sequence accessing a shared data structure d is interrupted by a handler that accesses d, the handler might find d in an inconsistent state, with unpredictable results.
- Declare global variables with
volatile.If the handler updates a global variable
g, andmainperiodically readsg, an optimizing compiler may decide that the value ofgnever changes inmain, and thus it would be safe to use a copy ofgthat is cached in a register. →mainwould never see the updated values from the handler!⇒ Declare a variable with the
volatiletype qualifier.volatile int g;volatilequalifier forces the compiler to read the value ofgfrom memory each time it is referenced in the code.As with any shared data structure, each access to a global variable should be protected by temporarily blocking signals.
- Declare flags with
sig_atomic_tOne common handler design - The handler records the receipt of the signal by writing to a global flag. The main program periodically reads the flag, responds to the flag, and clears the flag.
Use an integer data type
sig_atomic_tfor flags → Reads & writes for flags are guaranteed to be atomic(uninterruptible) because they can be implemented with a single instruction :volatile sig_atomic_t flag;The guarantee of atomicity only applies to individual reads and writes. - Does not apply to updates such as
flag++orflag = flag + 10, which might require multiple instructions.
- Keep handlers as simple as possible.
Writing Signal Handlers : Correct Signal Handling
pendingbit vector contains only one bit for each type of signal → There can be at most one pending signal of any particular type.If two signals of type k are sent to a destination process while signal k is blocked because the process is currently executing a handler for signal k, then the second signal is simply discarded.
- Example Code :
signal1,signal2- The parent installs a
SIGCHLDhandler and then creates three children. In the meantime, the parent waits for a line of input from the terminal and then processes it. (infinite loop)
- When each child terminates, the kernel notifies the parent by sending it a
SIGCHLDsignal.
- The parent catches the
SIGCHLD, reaps one child, does some additional clean up work (modeled by thesleep), and then returns.
signal1is flawed because it assumes that signals are queued./* WARNING: This code is buggy! */ void handler1(int sig){ int olderrno = errno; if ((waitpid(-1, NULL, 0)) < 0) sio_error("waitpid error"); Sio_puts("Handler reaped child\n"); Sleep(1); errno = olderrno; } int main(){ int i, n; char buf[MAXBUF]; if (signal(SIGCHLD, handler1) == SIG_ERR) unix_error("signal error"); /* Parent creates children */ for (i = 0; i < 3; i++) { if (Fork() == 0) { printf("Hello from child %d\n", (int)getpid()); exit(0); } } /* Parent waits for terminal input and then processes it */ if ((n = read(STDIN_FILENO, buf, sizeof(buf))) < 0) unix_error("read"); printf("Parent processing input\n"); while (1) ; exit(0); }- Output
linux> ./signal1 Hello from child 14073 Hello from child 14074 Hello from child 14075 Handler reaped child Handler reaped child CR Parent processing inputchild process 14075 was never reaped and remains a zombie.
What happened ? :
- The first signal is received and caught by the parent.
- While the handler is processing the first signal, the second signal is delivered & added to the set of pending signals.
- While the handler is processing the first signal, the third signal arrives.
- Since there is already a pending
SIGCHLD, the thirdSIGCHLDis discarded.
- After the handler has returned, the parent receive the second signal. Then, the handler processes the second signal.
- There are no more pending
SIGCHLDsignals → The thirdSIGCHLDsignal has been lost.
To fix
signal1, modify theSIGCHLDhandler to reap as many zombie as possible each time it is invoked.void handler2(int sig){ int olderrno = errno; while (waitpid(-1, NULL, 0) > 0) { /* Reap as many zombie as possible */ Sio_puts("Handler reaped child\n"); } if(errno != ECHILD) Sio_error("waitpid error"); Sleep(1); errno = olderrno; }- Output
linux> ./signal2 Hello from child 15237 Hello from child 15238 Hello from child 15239 Handler reaped child Handler reaped child Handler reaped child CR Parent processing input - The parent installs a
- Example Code :
Writing Signal Handlers : Portable Signal Handling
Different systems have different signal-handling semantics.
To deal with this aspect, the
sigactionallows users to clearly specify the signal-handling semantics they want when they install a handler.#include <signal.h> int sigaction(int signum, struct sigaction *act, struct sigaction *oldact);The
Signalwrapper installs a signal handler with the following signal handling semantics:- Only signals of the type currently being processed by the handler are blocked.
- As with all signal implementations, signals are not queued.
- Interrupted system calls are automatically restarted whenever possible.
- Once the signal handler is installed, it remains installed until
Signalis called with ahandlerargument of eitherSIG_IGNorSIG_DFL.
handler_t *Signal(int signum, handler_t *handler){ struct sigaction action, old_action; action.sa_handler = handler; sigemptyset(&action.sa_mask); /* Block sigs of type being handled */ action.sa_flags = SA_RESTART; /* Restart syscalls if possible */ if(sigaction(signum, &action, &old_action) < 0) unix_error("Signal error"); return (old_action.sa_handler);
Synchronizing Flows to Avoid Nasty Concurrency Bugs
Programming concurrent flows that read & write the same storage locations can cause a subtle synchronization error.
- Example Code
In this code, the parent keeps track of its current children using entries in a global job list, with one entry per job.
addjob&deletejobadd and remove entries from the job list.Parent creates a new child process → adds the child to the job list → When reaping a zombie child in the
SIGCHLDhandler, it deletes the child from the job list./* WARNING: This code is buggy! */ void handler(int sig){ int olderrno = errno; sigset_t mask_all, prev_all; pid_t pid; Sigfillset(&mask_all); while ((pid = waitpid(-1, NULL, 0)) > 0) { /* Reap a zombie child */ Sigprocmask(SIG_BLOCK, &mask_all, &prev_all); deletejob(pid); /* Delete the child from the job list */ Sigprocmask(SIG_SETMASK, &prev_all, NULL); } if (errno != ECHILD) Sio_error("waitpid error"); errno = olderrno; } int main(int argc, char **argv){ int pid; sigset_t mask_all, prev_all; Sigfillset(&mask_all); Signal(SIGCHLD, handler); initjobs(); /* Initialize the job list */ while (1) { if ((pid = Fork()) == 0) { /* Child process */ Excve("/bin/date", argv, NULL); } Sigprocmask(SIG_BLOCK, &mask_all, &prev_all); /* Parent process */ addjob(pid); /* Add the child to the job list */ Sigprocmask(SIG_SETMASK, &prev_all, NULL); } exit(0); }In this code, there is a race between call to
addjobin the main routine and the call todeletejobin the handler.If the child process terminates before the parent executes
addjob, the kernel will deliver aSIGCHLDto parent. → When the parent becomes runnable, the kernel notices the pendingSIGCHLD& causes it to be received by running the signal handler in the parent. →deletejobin the handler is called beforeaddjob! (synchronization error)If the child process terminates after the parent executes
addjob, events occur in the correct order.
- Using
sigprocmaskto synchronize processesTo solve the problem, block
SIGCHLDbefore the call toforkand then unblock them only after callingaddjob. → Then, it is guaranteed that the child will be reaped after it is added to the job list.sigset_t mask_one; Sigaddset(&mask_one, SIGCHLD); while (1) { Sigprocmask(SIG_BLOCK, &mask_one, &prev_one); /* Block SIGCHLD */ if ((pid = Fork()) == 0) { Sigprocmask(SIG_SETMASK, &prev_one, NULL); /* Unblock SIGCHLD */ Execve("/bin/date", argv, NULL); } Sigprocmask(SIG_BLOCK, &mask_all, NULL); /* Parent process */ addjob(pid); /* Add the child to the job list */ Sigprocmask(SIG_SETMASK, &prev_one, NULL); /* Unblock SIGCHLD */ }The children inherit the
blockedset of their parents → We must unblock theSIGCHLDin the child before callingexecve.
- Example Code
Explicitly Waiting for Signals -
sigsuspendWhen a main program needs to explicitly wait for a certain signal handler to run, use
sigsuspend.#include <signal.h> int sigsuspend(const sigset_t *mask);sigsuspendtemporarily replaces the current blocked set withmask, and then suspend the process until the receipt of a signal whose action is either to run a handler or to terminate the process.The action is to terminate → The process terminates without returning from
sigsuspend.The action is to run a handler →
sigsuspendreturns after the handler returns, restoring the blocked set to its state whensigsuspendwas called.- Example Code
When a Linux shell creates a foreground job, it must wait for the job to terminate and be reaped by the
SIGCHLDhandler before accepting the next user command.#include "csapp.h" volatile sig_atomic_t pid; void sigchld_handler(int s){ int olderrno = errno; pid = Waitpid(-1, NULL, 0); errno = olderrno; } void sigint_handler(int s){} int main(int argc, char **argv){ sigset_t mask, prev; Signal(SIGCHLD, sigchld_handler); Signal(SIGINT, sigint_handler); Sigemptyset(&mask); Sigaddset(&mask, SIGCHLD); while (1) { Sigprocmask(SIG_BLOCK, &mask, &prev); /* Block SIGCHLD */ if (Fork() == 0) /* Child */ exit(0); /* Wait for SIGCHLD to be received */ pid = 0; while (!pid) sigsuspend(&prev); /* Optionally unblock SIGCHLD */ Sigprocmask(SIG_SETMASK, &prev, NULL); /* Do some work after receiving SIGCHLD */ printf("."); } exit(0); }
8.6 Nonlocal Jumps
8.6 Nonlocal Jumps
Nonlocal jump transfers control directly from one function to another currently executing function without having to go through the normal call-and-return sequence.
setjmp&longjmp#include <setjmp.h> int setjmp(jmp_buf env); int sigsetjmp(sigjmp_buf env, int savesigs);setjmpsaves the current calling environment (PC, stack pointer, general purpose registers, ...) in theenvbuffer, for later use bylongjmp, and returns 0.
- The value of
setjmpshould not be assigned to a variable, but can be safely used as a test in aswitchor conditional statement.
#include <setjmp.h> void longjmp(jmp_buf env, int retval); void siglongjmp(sigjmp_buf env, int retval);longjmprestores the calling environment from theenvbuffer, and then triggers a return from the most recentsetjmpcall that initializedenv. →setjmpreturns with the nonzero return valueretval.
- Example Code - Using nonlocal jumps to recover from error conditions
#include "csapp.h" jmp_buf buf; int error1 = 0; int error2 = 1; void foo(void), bar(void); int main(){ switch(setjmp(buf)) { case 0: foo(); break; case 1: printf("Detected an error1 condition in foo\n"); break; case 2: printf("Detected an error2 condition in foo\n"); default: printf("Unknown error condition in foo\n"); } exit(0); } /* Deeply nested function foo */ void foo(void){ if (error1) longjmp(buf, 1); bar(); } void bar(void){ if (error2) longjmp(buf, 2); }Nonlocal jumps permit an immediate return from a deeply nested function call, usually as a result of detecting some error condition.
- Example Code - Using nonlocal jumps to branch out of a signal handler to a specific code location
#include "csapp.h" sigjmp_buf buf; void handler(int sig){ siglongjmp(buf, 1); } int main(){ if (!sigsetjmp(buf, 1)) { Signal(SIGINT, handler); Sio_puts("starting\n"); } else Sio_puts("resetarting\n"); while(1) { Sleep(1); Sio_puts("processing...\n"); } exit(0); /* Control never reaches here */ }sigsetjmpandsiglongjmpare versions ofsetjmpandlongjmpthat can be used by signal handlers.
- Each time the user types Ctrl+C, the handler performs a nonlocal jump back to the beginning of the
main, printing ‘restarting\n’.
- To avoid a race, we must install the handler after we call
sigsetjmp. If not, handler can run before the initial call tosigsetjmp.
sigsetjmpandsiglongjmpare not on the list of async-signal-safe functions → We must call only safe functions in any code reachable from asiglongjmp.
Leave a comment