CS:APP Chapter 7 Summary 🔗
Recently, I’ve been studying CS:APP - I’m posting my own summary of chapter 7 that I wrote up using Notion.
7.1 Compiler Drivers
7.1 Compiler Drivers
Most compilation systems provide a compiler driver that invokes the language preprocessor, compiler, assembler, and linker.
Example :
/* main.c */
int sum(int *a, int n);
int array[2] = {1, 2};
int main(){
int val = sum(array, 2);
return val;
}
/* sum.c */
int sum(int *a, int n){
int i, s = 0;
for(i = 0; i < n; i++){
s += a[i];
}
return s;
}To build example program above using the GNU compilation system, invoke the GCC driver by typing the following command : linux> gcc -0g -o prog main.c sum.c
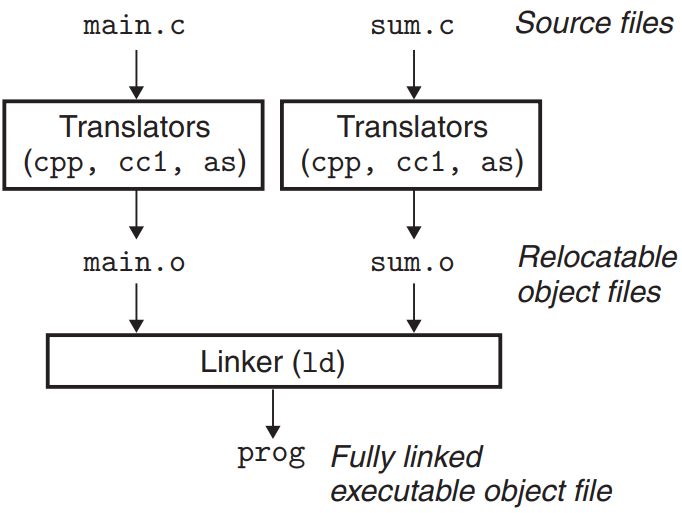
Then, the driver follows next steps :
- Run C preprocessor
cpp- translates the C source filemain.cinto an ASCII intermediate filemain.i:cpp [other arguments] main.c /tmp/main.i
- Run C compiler
cc1- translatesmain.iinto an ASCII assembly-language filemain.s:cc1 /tmp/main.i -0g [other arguments] -o /tmp/main.s
- Run assembler
as- translatesmain.sinto a binary relocatable object filemain.o:as [other arguments] -o /tmp/main.o /tmp/main.s
- Go through the same process to generate
sum.o.
- Run linker program
ld- combinesmain.o,sum.o, and necessary system object files to create the binary executable object fileprog:ld -o prog [system object files and args] /tmp/main.o /tmp/sum.o
To run the executable prog, type its name on shell’s command : linux> ./prog. Then, the shell invokes a function in OS called the loader - copies the code and data in prog into memory, and then transfers control to the beginning of the program.
7.2 Static Linking
7.2 Static Linking
- Static linker’s input : relocatable object files & command-line arguments
Relocatable object files consist of various code and data sections - each section is a contiguous sequence of bytes. Instructions, initialized global variables, and uninitialized variables are in different section respectively.
- Static linker’s output : fully linked executable object file.
- Linker’s two main tasks
- Symbol resolution
Object files define and reference symbols, where each symbol corresponds to a function, a global var, or a static var. The linker associates each symbol reference with a symbol definition.
- Relocation
Compilers & assemblers generate code and data sections that start at address 0. The linker relocates sections by associating a memory location with each symbol definition, and modifying all references to point to this memory location. The linker blindly performs these relocations using relocation entries, which is detailed instructions generated by the assembler.
- Linkers have minimal understanding of the target machine - The compilers & assemblers have already done most of the work.
7.3 Object Files
7.3 Object Files
Object files come in three forms :
- Relocatable object file : Contains binary code & data in a form that can be combined with other relocatable object files at compile time to create an executable object file.
- Executable object file : Contains binary code & data in a form that can be copied directly into memory and executed.
- Shared object file : A special type of relocatable object file that can be loaded into memory and linked dynamically, at either load time or run time.
Compilers & assemblers generate relocatable object files or shared object file, while linkers generate executable object files.
Object files are organized according to specific object file formats, which vary from system to system.
7.4 Relocatable Object Files
7.4 Relocatable Object Files
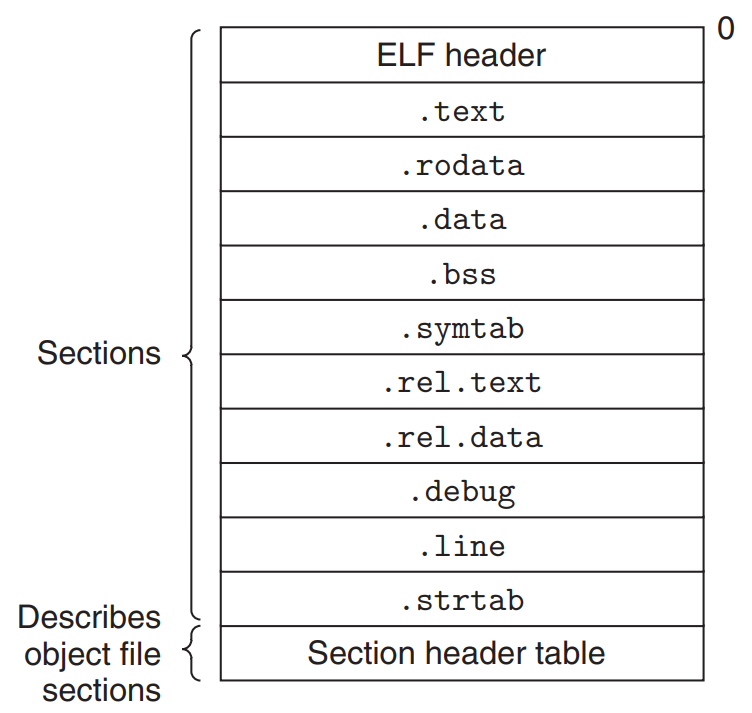
Format of a typical ELF relocatable object files
- ELF header
- describes word size and byte ordering of the system
- contains information for parsing and interpreting the object file :
- the size of ELF header
- the object file type (example : relocatable, executable, or shared)
- the machine type (example : x86-64)
- the file offset of the section header table
- the size and number of entries in the section header table
- Section header table
- describes the locations and sizes of the various sections
- contains a fixed-size entry for each section in the object file
.text: The machine code of the compiled program
.rodata: Read-only data (example : format strings inprintfstatements, and jump tables for switch statements)
.data: Initialized global and static C variables
.bss: Uninitialized global and static C variables, and any global or static variables that are initialized into 0.- This section occupies no actual space in the object file.
💡Object file formats distinguish between initialized and uninitialized variables for space efficiency : uninitialized variables don’t have to occupy any disk space in the object file. At run time, these variables are allocated in memory with an initial value of zero.💡Local C variables are maintained at run time on the stack, and don’t appear in either the.dataor.bsssections.
.symtab: A symbol table with information about functions and global variables.- doesn’t contain entries for local variables.
.rel.text: A list of locations in the.textsection that will need to be modified when the linker combines this object file with others.- example : instruction that calls an external function or references a global variable
- instructions that call local functions don’t need to be modified.
- Relocation information is not needed in executable object files → usually omitted in executable object files
.rel.data: Relocation information for global variables. (example : any initialized global variable whose initial value is the address of a global variable, or externally defined function)
.debug: A debugging symbol table. Only present if the compiler driver is invoked with the-goption.
.line: A mapping between line numbers in the original C source program and machine code instructions in the.textsection. Only present if the compiler driver is invoked with the-goption.
.strtab: A string table for the symbol tables in the.symtaband.debugsections and for the section names in the section headers. A sequence of null-terminated character strings.
7.5 Symbols and Symbol Tables
7.5 Symbols and Symbol Tables
Each relocatable object module, m, has a symbol table that contains information about the symbols that are defined & referenced by m.
Global Symbols, Externals, and Local Symbols
There are 3 different kinds of symbols :
- Global symbols : defined by m and can be referenced by other modules. → nonstatic C functions and global variables
- Externals : referenced by m but defined by some other modules. → nonstatic C functions and global variables that are defined in other modules.
- Local symbols : defined & referenced exclusively by m. → static C functions and global variables that are defined with
staticattribute.
💡Local linker symbols ≠ Local program variables : The symbol table doesn’t contain any symbols that correspond to local nonstatic program variables. These are managed at run time on stack.Local procedure variables that are defined with
staticattribute are not managed on the stack - The compiler allocates space in.dataor.bssfor each definition and creates a local linker symbol in the symbol table with a unique name.int f(){ static int x = 0; return x; } int g(){ static int x = 1; return x; }⇒ The compiler exports a pair of local linker symbols with different names to the assembler. (example :
x.1for the definition inf, andx.2for the definition ing.)
ELF Symbol Table Entry
Symbol tables are built by assemblers, using symbols exported by the compiler into to assembly-language
.sfile.The format of ELF symbol table entry :
typedef struct{ int name; /* String table offset */ char type:4, /* Function or data (4 bits) */ binding:4; /* Local or global (4 bits) */ char reserved; /* Unused */ short section; /* Section header index */ long value; /* Section offset or absolute address */ long size; /* Object size in bytes */ } Elf64_Symbol;name: a byte offset into the string table that points to the null-terminated string name of the symbol.
type: data or function
binding: indicates whether the symbol is local or global
section: an index into the section header table that indicates which section the symbol is assigned to
value: the symbol’s address - an offset from the beginning of the section where the object is defined for relocatable modules, and an absolute run-time address for executable object files.
size: the size of the object in bytes
Pseudosections
There are 3 special pseudosections that exist only in relocatable object files, and don’t have entries in the section header table :
- ABS : for symbols that should not be relocated
- UNDEF : for undefined symbols - symbols that are referenced in this object module but defined elsewhere
- COMMON : for uninitialized data objects that are not yet allocated
- For COMMON symbols, the
valuefield gives the alignment requirement, andsizegives the minimum size.
- COMMON vs.
.bss→ explained in Section 7.6- COMMON : Uninitialized global variables
.bss: Uninitialized static variables, & global or static variables that are initialized to zero
- For COMMON symbols, the
7.6 Symbol Resolution
7.6 Symbol Resolution
Symbol Resolution for Local Symbols
Symbol resolution for local symbols is straightforward - the compiler allows only one definition of each local symbol per module, and ensures that static local variables have unique names.
Symbol Resolution for Global Symbols
- Undefined Global Symbol
When the compiler encounters a symbol that is not defined in current module, it generates a linker symbol table entry assuming it is defined in some other module, and leaves it for the linker to handle. → If the linker can’t find a definition in any of its input modules, it prints an error message and terminates.
- Resolving Duplicate Symbol Names
Multiple object modules might define global symbols with the same name. Linux compilation system solve duplicate symbol names as below :
- At compile time, the compiler exports each global symbol to the assembler as either strong or weak.
- Strong symbol : Functions & initialized global variables
- Weak symbol : Uninitialized global variables
- The assembler encodes this information implicitly in the symbol table of the relocatable object file.
- Given this notion of strong and weak symbols, Linux linkers use the following rules for dealing with duplicate symbol names :
Rule 1. Multiple strong symbols with the same name are not allowed.
Rule 2. Given a strong symbol & multiple weak symbols with the same name, choose the strong symbol.
Rule 3. Given multiple weak symbols with the same name, choose any of the weak symbols.
- Example Code - Duplicate Symbol Definitions Having Different Types
/* foo5.c */ #include <stdio.h> void f(void); int y = 15212; int x = 15213; //strong symbol int main(){ f(); printf("x = 0x%x y = 0x%x \n", x, y); return 0; } /* bar5.c */ double x; //weak symbol void f(){ x = -0.0; }The linker will choose the strong symbol according to rule 2. → Since
doubleis 8 bytes andintis 4 bytes, the address ofxis0x601020, and the address ofyis0x601024→ The assignmentx = -0.0inbar5.cwill overwrite the memory locations forxandy. ⇒ The output isx = 0x0 y = 0x80000000.
- COMMON vs.
.bssThe compiler uses a seemingly arbitrary convention to assign symbols to COMMON and
.bss- This is because the linker allows multiple modules to define global symbols with the same name in some cases.When the compiler encounters a weak global symbol,
x, it doesn’t know if other modules also definex→ It can’t predict which of the multiple instances ofxthe linker might choose. → The compiler defers the decision to the linker by assigningxto COMMON.On the other hand, if
xis initialized to zero, then it’s strong symbol →xmust be unique by rule 2 → The compiler can confidently assign it to.bss.Similarly, static symbols are unique by construction → The compiler can confidently assign them to either
.dataor.bss.
Linking with Static Libraries
- Static Library
Static library is a single file which is a package of related object modules. Static libraries can be supplied as input to the linker - When the linker builds the output executable, it copies only the object modules that are referenced by the application program.
- Why use libraries?
To understand why do systems support the notion of the libraries, let’s consider the different approaches that compiler developers might use to provide functions to users.
- Having the compiler recognize calls to the standard functions
- Convenient to application programmers 👍
- Add significant complexity to the compiler 👎
- Would require a new compiler version each time functions were modified 👎
- Putting all of the standard C functions in a single relocatable object module
- Would decouple the implementation of the standard functions from the implementation of the compiler 👍
- Convenient to application programmers 👍
- Every executable file would contain a complete copy of the collection of standard functions → Extremely wasteful of disk space 👎
- Each running program would contain a copy of the functions in memory → Extremely wasteful of memory 👎
- Any change to any standard function would require the re-compilation of the entire source file 👎
- Creating a separate relocatable file for each standard function
- Require application programmers to explicitly link the appropriate object modules → error prone & time consuming 👎
- Advantages of Static libraries
- Application programmers can use any functions in the library by specifying a single filename :
linux> gcc main.c /user/lib/libm.a /user/lib/libc.a→ Convenient! 👍
- The linker will only copy the object modules that are referenced by the program → Reduced size of the executable on disk and in memory 👍
- Application programmers can use any functions in the library by specifying a single filename :
- Having the compiler recognize calls to the standard functions
- Linking with Static Libraries
On Linux systems, static libraries are stored in a particular file format, archive.
Archive is a collection of concatenated relocatable object files + a header that describes the size & location of each object files. Archive filenames are denoted with the
.asuffix./* addvec.o */ int addcnt = 0; void addvec(int *x, int *y, int *z, int n){ int i; addcnt++; for(i = 0; i < n; ++i){ z[i] = x[i] + y[i]; } } /* main2.o */ #include <stdio.h> #include "vector.h" int x[2] = {1, 2}; int y[2] = {3, 4}; int z[2]; int main(){ addvec(x, y, z, 2); printf("z = [%d %d]\n", z[0], z[1]); return 0; }- To create a static library of a function
addvec, use theARtool :linux> gcc -c addvec.c [other .c files]→linux> ar rcs libvector.a addvec.o [other .o files]
- To use the library, write an application
main2.cwhich invokes theaddveclibrary routine.vector.hdefines the function prototypes for the routines inlibvector.a.
- To build the executable, compile and link the input files
main2.o&libvector.a:linux> gcc -c main2.c→linux> gcc -static -o prog2c main2.o ./libvector.a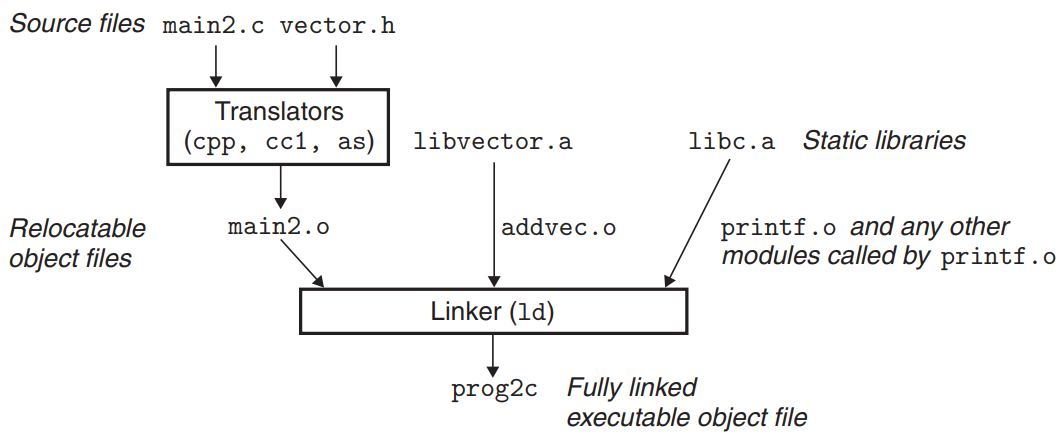
The linker determines that the
addvecsymbol is referenced bymain2.o→ It copiesaddvec.ointo the executable.The linker also copies the
printf.omodule fromlibc.a, along with a number of other modules from the C run-time system.The program doesn’t reference any symbols defined by other modules → The linker doesn’t copy any other modules into the executable.
- To create a static library of a function
- Static Library
How Linkers Use Static Libraries to Resolve References
During the symbol resolution phase, the linker scans the relocatable object files & archives in the same order they appear on the command line.
During this scan, the linker maintains a set E, U, D, which are initially empty :
- Set E : A set of relocatable object files that will be merged to form the executable
- Set U : A set of unresolved symbols (example : symbols referred to but not yet defined)
- Set D : A set of symbols that have been defined in previous input files.
Linker resolves references following the next algorithm :
- For each file f on the command line, determine if f is an object file or an archive.
- f is an object file → Add f to E, update U & D to reflect symbol definitions & references in f, and proceed to the next input file.
- f is an archive → Attempt to match the unresolved symbols in U against the symbols in the archive.
- Some archive member m defines a symbol that resolves a reference in U → Add m to E, and update U & D to reflect the symbol definitions and references in m.
- Iterate the member object files in the archive until a fixed point is reached where U & D no longer change.
- After the iteration is over, discard any member object files not contained in E.
- Proceed to the next input file.
- After the scanning, U is empty → Merge & relocate the object files in E to build the output executable file.
- After the scanning, U isn’t empty → Print an error and terminate.
If the library that defines a symbol appears on the command line before the object file that references that symbol, then the reference won’t be resolved and linking will fail! (example :
linux> gcc -static ./libvecctor.a main2.c→ Error occurs due to an undefined reference toaddvec.)⇒ Place libraries at the end of the command line.
If the libraries are not independent, they must be ordered so that for each symbol s that is referenced externally by a member of an archive, at least one definition of s follows a reference to s on the command line. Libraries can be repeated on the command line if necessary to satisfy the dependence requirements. (example :
linux> gcc foo.c libx.a liby.a libx.a)
7.7 Relocation
7.7 Relocation
Once the linker has completed the symbol resolution step, the linker is now ready to begin the relocation step, where it merges the input modules and assigns run-time addresses to each symbol.
Two Steps of Relocation
- Relocating sections & symbol definitions
- The linker merges all sections of the same type into a new aggregate section of the same type. (example :
.datasections from input modules are all merged into one.datasection for the output executable object file.)
- The linker assigns run-time memory addresses to the new aggregate sections, to each section defined by the input modules, and to each symbol.
- The linker merges all sections of the same type into a new aggregate section of the same type. (example :
- Relocating symbol references within sections
- The linker modifies every symbol references in the code and data sections so that they point to the correct run-time addresses.
- Relocating sections & symbol definitions
Relocation Entries
When the assembler encounters a reference to an object whose ultimate location is unknown, it generates a relocation entry that tells the linker how to modify the reference when it merges the object file into an executable. Relocation entries for code are placed in
.rel.text, and relocation entries for data are placed in.rel.data.typedef struct { long offset; /* Offset of the reference to relocate */ long type:32, /* Relocation type */ symbol:32; /* Symbol table index */ long addend; /* Constant part of relocation expression */ } Elf64_Rela;offset: the section offset of the reference that needs to be modified.
type: how the linker modify the new reference - ELF defines 32 different relocation types. Two most basic relocation types are :R_X86_64_PC32: Relocate a reference that uses a 32-bit PC-relative address.
R_X86_64_32: Relocate a reference that uses a 32-bit absolute address.
symbol: identifies the symbol that the modified reference should point to.
addend: a signed constant that is used by some types of relocations to bias the value of the modified reference.
Relocating Symbol References
The pseudo-code for the linker’s relocation algorithm :
foreach section s { foreach relocation entry r { refptr = s + r.offset; /* ptr to reference to be relocated */ /* Relocate a PC-relative reference */ if (r.type == R_X86_64_PC32) { refaddr = ADDR(s) + r.offset; /* ref's run-time address */ *refptr = (unsigned) (ADDR(r.symbol) + r.addend - refaddr); } /* Relocate an absolute reference */ if (r.type == R_X86_64_32) *refptr = (unsigned) (ADDR(r.symbol) + r.addend); } }This code assumes that the linker has already chosen run-time addresses for each section (
ADDR(s)) and each symbol (ADDR(r.symbol)).- Example of Relocating Symbol References :
main.ofor the C code in Section 7.1(This code is generated by the GNU OBJDUMP tool - relocation entries and instructions are actually stored in different sections.)
0000000000000000 <main>: 0: 48 83 ec 08 sub $0x8,%rsp 4: be 02 00 00 00 mov $0x2,%esi 9: bf 00 00 00 00 mov $0x0,%edi // %edi = &array. '00 00 00 00' is the reference to array that needs to be modified. a: R_X86_64_32 array // Relocation entry e: e8 00 00 00 00 callq 13 <main+0x13> // sum(). '00 00 00 00' is the reference to array that needs to be modified. f: R_X86_64_PC32 sum-0x4 13: 48 83 c4 08 add $0x8,%rsp 17: c3 retq- Relocating PC-Relative References
- At section offset
0xe, thecallinstruction begins, followed by a placeholder for the 4 byte PC-relative reference to the targetsum. The corresponding relocation entryrconsists of 4 fields :r.offset = 0xf: the reference part starts from the section offset0xf.r.symbol = sumr.type = R_X86_64_PC32r.append = -4: the placeholder is 4 byte long.
- Suppose that the linker has determined that
ADDR(s) = ADDR(.text) = 0x4004d0, andADDR(r.symbol) = ADDR(sum) = 0x4004e8.
- Using the relocation algorithm, the linker first computes the run-time address of the reference :
refaddr = ADDR(s) + r.offset = 0x4004d0 + 0xf = 0x4004df
- Then the linker updates the reference so that it will point to the
sumat the run time :*refptr = (unsigned) (ADDR(r.symbol) + r.addend - refaddr) = 0x4004e8 + (-4) - 0x4004df = 0x5
- In the resulting executable object file, the
callinstruction has the following relocated form :4004de: e8 05 00 00 00 callq 4004e8 <sum>.
- At run time, when the CPU executes the
call, the PC has a value of0x4004e3. To execute thecall, the CPU performs the following steps :- Push PC onto stack
- PC ← PC +
0x5=0x4004e3+0x5=0x4004e8=sum's address!
- At section offset
- Relocating Absolute References
- At section offset
0x9, themovinstruction begins, followed by a placeholder for the 4 byte absolute reference toarray. The corresponding relocation entryrconsists of 4 fields :r.offset = 0xa: the reference part starts from the section offset0xa.r.symbol = arrayr.type = R_X86_64_32r.append = 0
- Suppose that the linker has determined that
ADDR(r.symbol) = ADDR(array) = 0x601018.
- Using the relocation algorithm, the linker updates the reference :
*refptr = (unsigned) (ADDR(r.symbol) + r.addend) = 0x601018 + 0 = 0x601018
In the resulting executable object file, the reference has the following relocated form :
4004d9: bf 18 10 60 00 mov $0x601018,%edi. - At section offset
- Example of Relocating Symbol References :
7.8 Executable Object Files
7.8 Executable Object Files
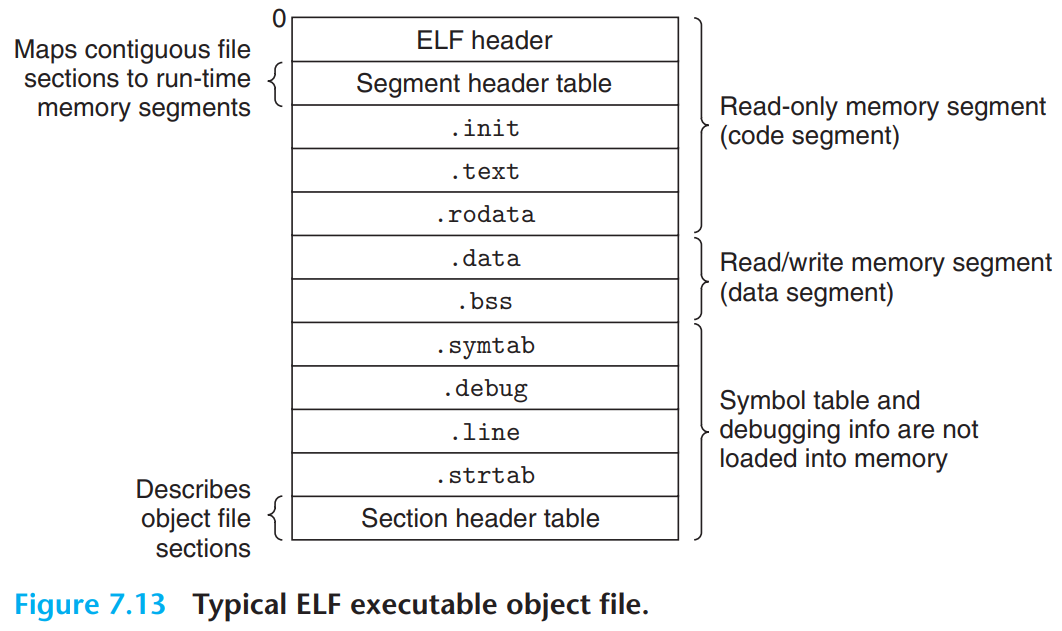
- ELF header : describes the overall format of the file & includes program’s entry point(the address of the first instruction to execute).
- Segment header table
In ELF executable, contiguous chunks of the executable file are mapped to contiguous memory segments. This mapping is described by segment header table (= program header table).

off: the offset of the segment’s first section in the object file
vaddr/paddr: the starting address of the segment in the memoryThe linker must choose
vaddrsuch thatvaddrmodalign=offmodalign. This alignment requirement is an optimization that enables efficient transfer of segments in the object files to memory.
align: alignment requirement (2**21 =0x200000)
filesz: segment size in object file
memsz: segment size in memory
flags: run-time permissions (r-x= read/execute permissions,rw-= read/write permissions)
For example, there are 2 segments in the program header table in Figure 7.14 - code segment(ELF header, program header table,
.init,.text,.rodata) in Line 1, 2, and data segment(.data,.bss) in Line 3, 4.Data segment has a total memory size of
0x230bytes, and initialized with the0x228bytes in the.datasection starting at offset0xdf8in the object file. The remaining 8 bytes correspond to.bssdata that will be initialized to 0 at run time. (.bssoccupies no actual space in object file!)
.init: defines a function_init, that will be called by the program’s initialization code.
.text,.rodata,.data: similar to those in a relocatable object file, except that these sections have been relocated to their run-time memory addresses.
- Executable is fully linked → There are no
.rel.sections.
7.9 Loading Executable Object Files
7.9 Loading Executable Object Files
When we type executable object file’s name to the Linux shell’s command line, the shell runs the file by invoking loader - memory resident operating system code.
The loader copies the code & data in the executable object file from disk into memory, and runs the program by jumping to its entry point. The loader can be invoked by calling the execve function.
Run-time Memory
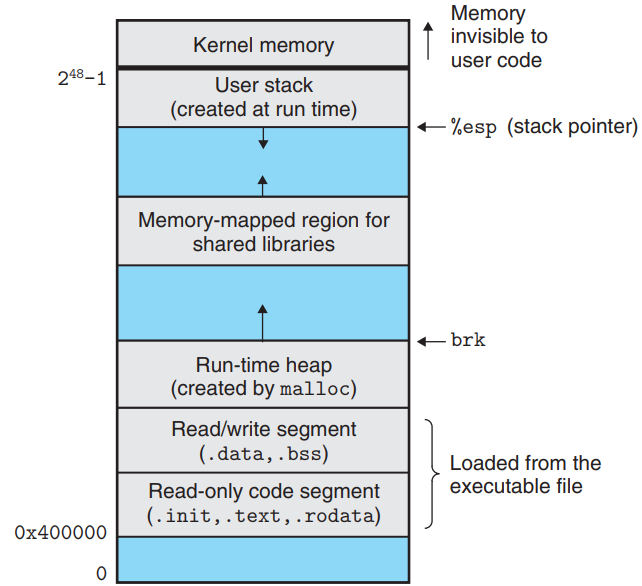
- On Linux x86-64 systems, the code segment(
.init,.text,.rodata) starts at address0x400000, followed by the data segments(.data,.bss).
- The run-time heap follows the data segment, and grows upward via calls to the
malloclibrary.
- The region for shared modules follows the run-time heap.
- The user stack starts below the largest legal user address , and grows down.
- The kernel memory, which is the memory-resident part of the OS, is above the stack.
- In practice, there is a gap between the code and data segments due to the alignment requirement on
.datasegment, and the usage of address-space layout randomization(ASLR) when the linker assigns run-time addresses to the stack, shared library and heap segments.
- On Linux x86-64 systems, the code segment(
Loading Executable Object Files
- The loader creates a rum-time memory.
- The loader copies chunks of the executable object file into the code & data segments.
- The loader jumps to the programs’ entry point, which is always the address of the
_startfunction._startis defined in the system object filecrt1.o, and is the same for all C programs._startcalls the system startup function,__libc_start_main, which is defined inlibc.so.__libc_start_maininitializes the execution environment, calls the user-levelmainfunction, handles its return value, and if necessary returns control to the kernel.
7.10 Dynamic Linking with Shared Libraries
7.10 Dynamic Linking with Shared Libraries
Disadvantages of Static Libraries
- Static libraries need to be maintained and updated periodically. If updated, programmers must explicitly re-link their programs against the updated library.
- Almost every C program uses standard I/O functions(
printf,scanf, ...) → the code for these functions is duplicated in the text segment of each running process. → Can be a waste of memory resources on a system running hundreds of processes.
Shared library
A shared library is an object module that can be loaded at an arbitrary memory address and linked with a program in memory at either run time or load time. → Dynamic linker performs this process called dynamic linking.
Shared libraries are indicated by the
.sosuffix.Shared libraries are shared in 2 ways :
- There is only one
.sofile for a particular library. The code & data in this.sofile are shared by all executable object files that reference this library.↔ Static library’s contents are copied and embedded in each executables that reference them.
- A single copy of the
.textsection of a shared library in memory can be shared by different running processes.
- There is only one
Dynamic Linking process
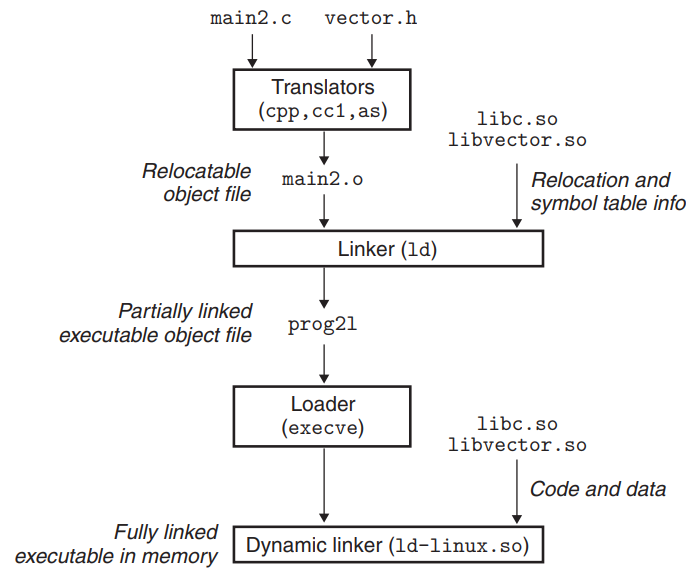
This process is for the case in which the dynamic linker loads and links shared libraries when an application is loaded.
The basic idea is to do some of the linking statically when the executable file is created, and then complete the linking process dynamically when the program is loaded.
- To create the library, invoke the compiler driver with some special directives to the compiler and linker :
linux> gcc -shared -fpic -o libvector.so addvec.c multvec.c-fpic: directs the compiler to generate position-independent code.-shared: directs the linker to create a shared object file.
- Link it into different object files :
linux> gcc -o prog21 main2.c ./libvector.so→ An executable object file
prog21is created in a form that can be linked withlibvector.soat run time.※ None of the code or data sections from
libvector.soare copied into theprog21. Instead, the linker copies some relocation & symbol table information that will allow references to code and data inlibvector.soto be resolved at load time.
- When the loader loads & run
prog21, the loader loads the partially linked executableprog21.
- The loader notices that
prog21contains a.interpsection, which contains the path name of the dynamic linker.
- The loader loads & runs the dynamic linker.
- The dynamic linker finishes the linking task by performing following relocations :
- Relocating the text and data of
libc.sointo some memory segment
- Relocating the text and data of
libvector.sointo some another memory segment
- Relocating any references in
prog21to symbols defined bylibc.soandlibvector.so
- Relocating the text and data of
- The dynamic linker passes control to the application.
- To create the library, invoke the compiler driver with some special directives to the compiler and linker :
7.11 Loading and Linking Shared Libraries from Applications
7.11 Loading and Linking Shared Libraries from Applications
It is also possible for an application to request the dynamic linker to load and link arbitrary shared libraries while the application is running.
Linux system provide a simple interface to the dynamic linker that allows application programs to load and link shared libraries at run time :
#include <dlfcn.h>
// dlopen function loads and links the shared library 'filename'. returns pointer to handle if OK, NULL on error.
void *dlopen(const char *filename, int flag);
// dlsym takes a handle to a previously opened shared library and a symbol name, and returns the address of the symbol if it exists. returns NULL otherwise.
void *dlsym(void *handle, char *symbol);
// dlclose unloads the shared library if no other shared libraries are still using it. returns 0 if OK, -1 on error.
int dlclose (void *handle);
// dlerror returns a string describing the most recent error that occured, or NULL if no error occured.
cost char *dlerror(void);7.12 Position-Independent Code (PIC)
7.12 Position-Independent Code (PIC)
Modern systems compile the code segments of shared modules so that they can be loaded anywhere in memory without having to be modified by the linker. → A single copy of shared module’s code segment can be shared by several processes.
Position-independent code (PIC) is the code that can be loaded without any relocations.
References to external procedures and global variables that are defined by shared modules require some special techniques :
PIC Data Reference
The distance between any instruction in the code segment and any variable in the data segment is a run-time constant. → Compilers that want to generate PIC references to global variables exploit this fact by creating a table called the global offset table (GOT) at the beginning of the data segment.
- The GOT contains an 8-byte entry for each global procedure or variable that is referenced by the object module.
- The compiler also generates a relocation record for each entry in the GOT.
- At load time, the dynamic linker relocates each GOT entry so that it contains the absolute address of the object.
- Using GOT to reference a global variable
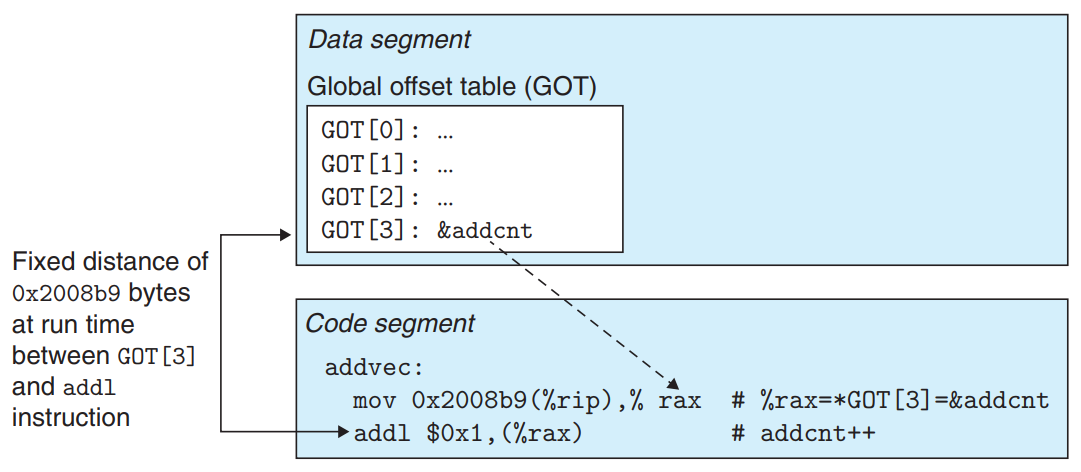
addvecin code segment loads the address of the global variableaddcntindirectly viaGOT[3]:mov 0x2008b9(%rip), %rax%ripat this moment is the address of the instructionaddl $0x1, (%rax), and0x2008b9is the distance betweenGOT[3]and%rip.
PIC Function Calls
GNU compilation system uses an technique called lazy binding that defers the binding of each procedure address until the first time the procedure is called.
→ By deferring the resolution of a function’s address until it is actually called, the dynamic linker can avoid hundreds or thousands of unnecessary relocations at load time.
Lazy binding is implemented with a interaction between the GOT and the procedure linkage table (PLT).
- The contents of PLT
- The PLT is part of the code segment.
- The PLT is an array of 16-byte code entries. Each shared library function called by the executable has its own PLT entry. Each of these entries is responsible for invoking a specific function.
PLT[0]is a special entry that jumps into the dynamic linker.
PLT[1]invokes the system startup function__libc_start_main(appeared in section 7.9).
- Entries starting at
PLT[2]invoke functions called by the user code.
- In the figure,
PLT[2]invokesaddvecandPLT[3](not shown) invokesprintf.
- Instructions of PLT entry (except for
PLT[0])- Jump to corresponding GOT entry
- Push ID for function onto the stack
- Jump to PLT[0]
- The contents of GOT
- The GOT is part of the data segment.
- The GOT is an array of 8-byte address entries.
- When used in conjunction with the PLT,
GOT[0]andGOT[1]contain information that the dynamic linker uses when it resolves function addresses.
GOT[2]is the entry point for the dynamic linker.
- Each of the remaining entries corresponds to a called function whose address needs to be resolved at run time.
- Each entries has a matching PLT entry. Initially, each GOT entry points to the second instruction in the corresponding PLT entry.
- In the figure,
GOT[4]andPLT[2]correspond toaddvec.
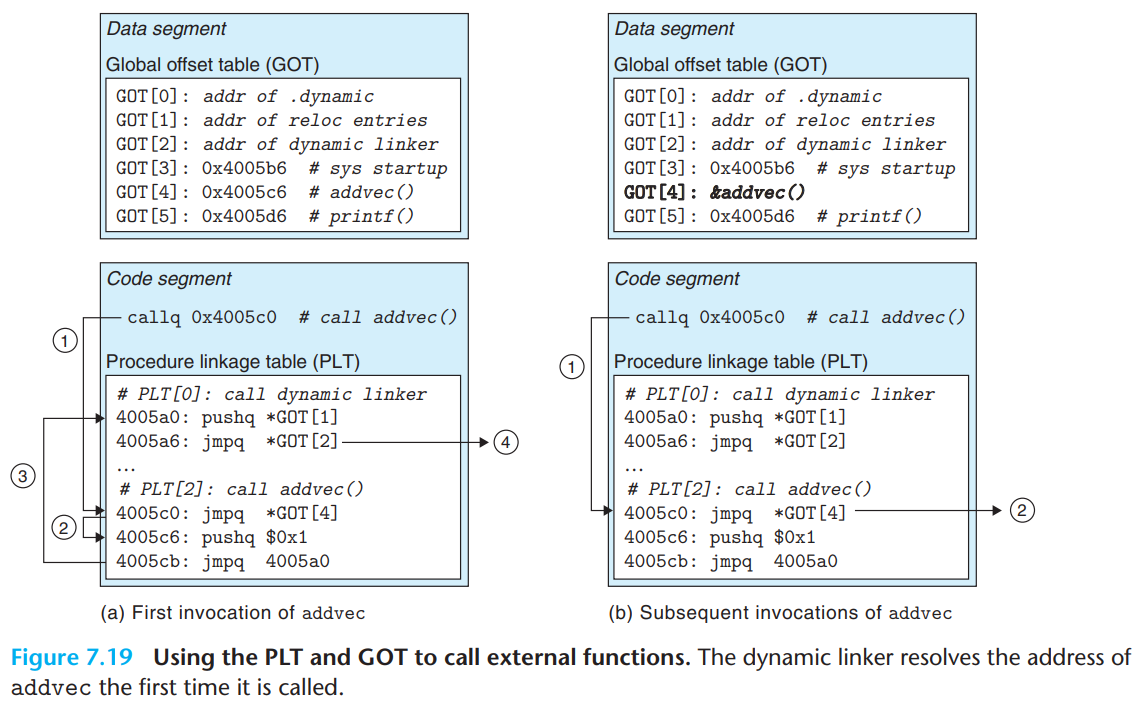
- Lazy binding - First invocation of
addvec- The program calls into
PLT[2]- the PLT entry foraddvec.
- The first PLT instruction does an indirect jump through
GOT[4]:jmpq *GOT[4]The initial GOT entries point to the second instruction (
0x4005c6) in its corresponding PLT entry → The indirect jump transfers control back to the next instruction inPLT[2].
- After pushing an ID for
addvec(0x1) onto the stack,PLT[2]jumps toPLT[0]:pushq $0x1,jmpq 4005a0
PLT[0]pushes an argument for the dynamic linker indirectly throughGOT[1](address of relocation entries) :pushq *GOT[1]and then jumps into the dynamic linker indirectly through
GOT[2]:jmpq *GOT[2]
- The dynamic linker uses the two stack entries (
0x1,*GOT[1]) to determine the run-time location ofaddvec, overwritesGOT[4]with this address, and passes control toaddvec.
- The program calls into
- Lazy binding - Subsequent invocations of
addvec- Control passes to
PLT[2].
- The indirect jump through
GOT[4]transfers control directly toaddvec:jmpq *GOT[4]
- Control passes to
- The contents of PLT

7.13 Library Interpositioning
7.13 Library Interpositioning
Library Interpositioning
Linux linkers support a library interpositioning that allows you to intercept calls to shared library functions and execute your own code. → You can trace the number of times a particular library function is called, validate and trace its input and output values, or replace it with a completely different implementation.
The basic idea of library interpositioning
- Given some target function to be interposed on, create a wrapper function whose prototype is identical to the target function, which typically executes its own logic, then calls the target function and passes its return value back to the caller.
- Using some particular interpositioning mechanism, we can trick the system into calling the wrapper function instead of the target function..
- Interpositioning can occur at compile time, link time, or run time as the program is being loaded and executed.
Leave a comment