CS:APP Chapter 6 Summary 📝
Recently, I’ve been studying CS:APP - I’m posting my own summary of chapter 6 that I wrote up using Notion.
6.1 Storage Technologies
6.1 Storage Technologies
RAM
SRAM & DRAM
- SRAM (Static RAM)
SRAM stores each bit in a bistable memory cell, which is implemented with a six-transistor circuit.
SRAM memory cell will retain its value indefinitely, as long as it is kept powered.
Even when a disturbance, such as electrical noise, perturbs the voltages, the circuit will return to the stable value when the disturbance is removed.
- DRAM (Dyanmic RAM)
DRAM stores each bit as charge on a capacitor, each cell consisting of a capacitor and a single access transistor. → DRAM storage can be made very dense.
DRAM is very sensitive to any disturbance → Exposure to light rays will cause the capacitor voltage to change.
DRAM’s memory system must periodically refresh every bit of memory by reading it out and then rewriting it.
- SRAM vs DRAM

- SRAM (Static RAM)
Conventional DRAMs and Enhanced DRAMs
- Conventional DRAMs
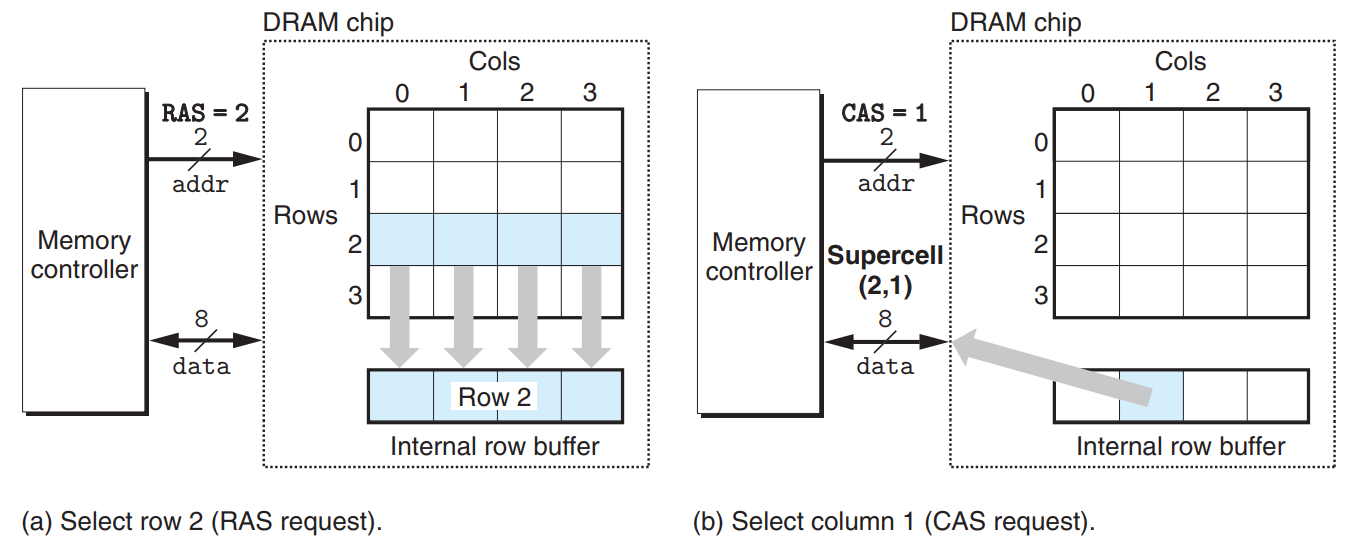
The cells in a DRAM chip are partitioned into d supercells, each consisting of w DRAM cells - d * w DRAM stores a total of dw bits of information.
The supercells are organized as a rectangular array with r rows and c columns, where rc = d. Each supercells has an address of the form (i, j).
Information flows in and out of the chip via external connectors called pins, each of which carries a 1-bit signal. - data pins transfer data in or out of the chip, and addr pins carry row and column supercell addresses.
Memory controller transfer w bits at a time to and from each DRAM chip.
To read the contents of supercell (i, j), the memory controller sends i, which is called a RAS (row access strobe) request, to the DRAM, followed by j, which is called a CAS (column access strobe) request. → DRAM responds by copying the entire contents of row i into an internal row buffer, then copying the w bits in supercell (i, j) from the row buffer and sending them to the memory controller.
Circuit designers organized DRAMs as two-dimensional arrays to reduce the number of address pins on the chip.
- Memory Modules

DRAM chips are packaged in memory modules that plug into expansion slots on the main system board.
The example module in figure stores a total of 64 MB using eight 64-Mbit 8M * 8 DRAM chips, numbered 0 to 7.
Each 64-bit word at byte address A in main memory is represented by the 8 supercells whose corresponding supercell address is (i, j).
To retrieve the word at memory address A, the memory controller converts A to a supercell address (i, j) and sends it to the memory module → The memory module sends i and j to DRAM → Each of DRAMs outputs 8-bit contents of its (i, j) supercell. → Circuitry in the module collects these outputs and forms them into a 64-bit word, which it returns to the memory controller.
Main memory can be aggregated by connecting multiple memory modules to the memory controller.
- Enhanced DRAMs
- Fast page mode DRAM (FPM DRAM) : allows consecutive accesses to the same row to be served directly from the row buffer.
- Extended data out DRAM (EDO DRAM) : An enhanced form of FPM DRAM that allows the individaul CAS signals to be spaced closer together in time.
- Synchronous DRAM (SDRAM) : uses the rising edges of the same external clock signal that drives the memory controller to communicate with the memory controller. → can output the contents at a faster rate.
- Double Data-Rate Synchronous DRAM (DDR SDRAM) : uses both clock edges as control signals.
- Video RAM (VRAM) : used in the frame buffers of graphics systems.
- Conventional DRAMs
Nonvolatile Memory
DRAMs and SRAMs are volatile - they lose their information if the supply voltage is turned off. ↔ Nonvolatile memories retain their information even when they are powered off.
Nonvolatile memories are referred to collectively as read-only memories(ROMs).
- Programmable ROM (PROM) : can be programmed exactly once.
- Erasable programmable ROM (EPROM)
EPROM has a transparent window that permits light to reach the storage cells - EPROM cells are cleared to zeros by shining ultraviolet light.
EPROM can be programmed by using a special device to write ones.
EPROM can be erased and reprogrammed on the order of 1,000 times.
- Electrically erasable PROM (EEPROM)
EEPROM is similar to EPROM, but doesn’t need a physically separate programming device - can be reprogrammed in-place on circuit cards.
EEPROM can be reprogrammed on the order of 100,000 times.
- Flash memory
Flash memory is a nonvolatile memory based on EEPROMs.
Solid state disk (SSD) is a new form of flash-based disk drive.
Programs stored in ROM devices are called firmware. When a computer system is powered up, it runs firmware stored in ROM.
Some systems provide a small set of primitive input and output functions in firmware. (example : PC’s BIOS (basic input/output system) routines)
Accessing Main Memory
Bus transaction is a series of steps required to transfer data between the CPU and memory. - read transaction : main memory → CPU, write transaction : CPU → main memory.
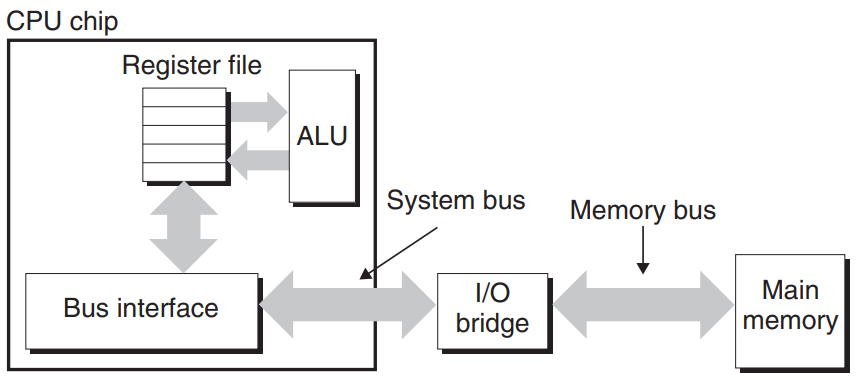
Main components of computer system are the CPU chip, I/O bridge, and the DRAM memory modules that make up main memory.
These components are connected by a system bus that connects the CPU to the I/O bridge, and a memory bus that connects the I/O bus to the main memory.
I/O bridge translates the electrical signals of the system bus into the electrical signals of the memory bus.
- Read transaction :
movq A, %rax
The bus interface, circuitry on the CPU chip, initiates a read transaction when CPU performs a load operation :
- CPU places the address
Aon the system bus. I/O bridge passes the signal along to the memory bus.
- Main memory senses the address signal on the memory bus, reads the address from the memory bus, fetches the data from the DRAM, and writes the data to the memory bus. I/O bridge translates the memory bus signal into a system bus signal and passes it along to the system bus.
- CPU senses the data on system bus, reads the data from the bus, and copies the data to
%rax.
- Write transaction :
movq %rax, A
- CPU places the address
Aon the system bus. The memory reads the address from the memory bus.
- CPU copies the data in
%raxto the system bus.
- The main memory reads the data from the memory bus and stores the bits in the DRAM.
- Read transaction :
Disk Storage
Disks are workhorse storage devices that hold enormous amounts of data, as opposed to a RAM-based memory.
Disk Geometry

Disks are constructed from platters. Each platter consists of two surfaces that are coated with magnetic recording material.
Each surface consists of a collection of concentric rings called tracks, each of which is partitioned into a collection of sectors. Each sector contains an equal number of data bits. Sectors are separated by gaps.
A disk consists of one or more platters stacked on top of each other - Cylinder is the collection of tracks on all the surfaces that are equidistant from the center of the spindle.
(example : if a drive has 3 platters and 6 surfaces, then cylinder k is the collection of the six instances of track k.)
Disk Capacity
- capacity : the maximum number of bits that can be recorded by a disk
- The factors that determine disk capacity
- Recording density (bits/in) : The number of bits that can be squeezed into 1 inch segment of a track.
- Track density (tracks/in) : The number of tracks that can be squeezed into a 1 inch segment of the radius extending from the center of the platter.
- Areal density () : The product of the recording density and the track density.
- Multiple zone recording
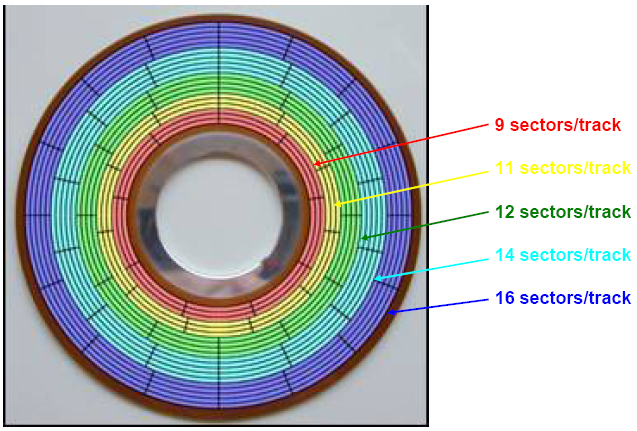
Modern high-capacity disks use multiple zone recording, where the set of cylinders is partitioned into disjoint subsets known as recording zones.
Each track in each cylinder in a zone has the same number of sectors, which is determined by the number of sectors that can be packed into the innermost track of the zone.
- Capacity of a disk
Disk Operation
- How disks read and write data
- Disks read and write bits using a read/write head connected to the end of an actuator arm. The drive position the head over the track on the surface by moving the arm. - This mechanical motion is known as a seek.
- As each bit on the track passes underneath, the head can sense the data or alter the data.
- Access time
The access time for a sector has 3 main components :
- Seek time
The time required to move the arm to position the head over the track that contains the target sector.
= 3~9ms
- Rotational latency
The time that drive waits for the first bit of the target sector to pass under the head.
,
- Transfer time
The time for drive to read or write the contents of the sector.
- Seek time
- Important points
- Access time is typically dominated by the seek time and the rotational latency.
- The disk access time is about 40,000 times greater than SRAM and about 2,500 times greater than DRAM for the example in the book.
Logical Disk Blocks
Modern disks present a simpler view of disk’s geometry as a sequence of B sector-size logical blocks, numbered 0, 1, ..., B-1.
Disk controller, a small hardware/firmware device in the disk package, maintains the mapping between logical block numbers and actual disk sectors.
- How OS reads a disk sector into main memory
- OS asks the disk controller to read a particular logical block number.
- Firmware on the controller performs a fast table lookup that translates the logical block number into a (surface, track, sector) triple.
- Hardware on the controller interprets this triple to move the heads to the appropriate cylinder.
- The head reads in the data, and the bits sensed are gathered up into a small memory buffer on the controller, then are copied into main memory.
Connecting I/O Devices

I/O devices are connected to the CPU and main memory using an I/O bus.
I/O bus is slower than the system and memory buses, but it can accommodate a wide variety of third-party I/O devices.
In a system with memory-mapped I/O, a block of addresses in the address space is reserved for communicating with I/O devices. Each of these addresses is known as an I/O port. Each device is associated with one or more ports.
- How CPU reads a disk sector
- CPU can initiate a disk read by executing three store instructions to the disk controller’s port :
- tells the disk to initiate a read, along with other parameters. (i.e. whether to interrupt the CPU when the read is finished)
- indicates the logical block number that should be read.
- indicates the main memory address where the contents of the disk sector should be stored.
- After the request, CPU will typically do other work while the disk is performing the read to minimize the waste of time.
- After the request, disk controller will read the contents of the sector, and transfer the contents directly to main memory, without any intervention from the CPU. → Direct memory access (DMA)
- After the DMA transfer is complete, the disk controller sends an interrupt signal to the CPU.
- CPU stops what it is currently working on and jump to an OS routine that records the fact that the I/O has finished and then returns control to the point where the CPU was interrupted.
Solid State Disks (SSD)
Solid state disks (SSD) is a storage technology based on flash memory that behaves like any other disk.
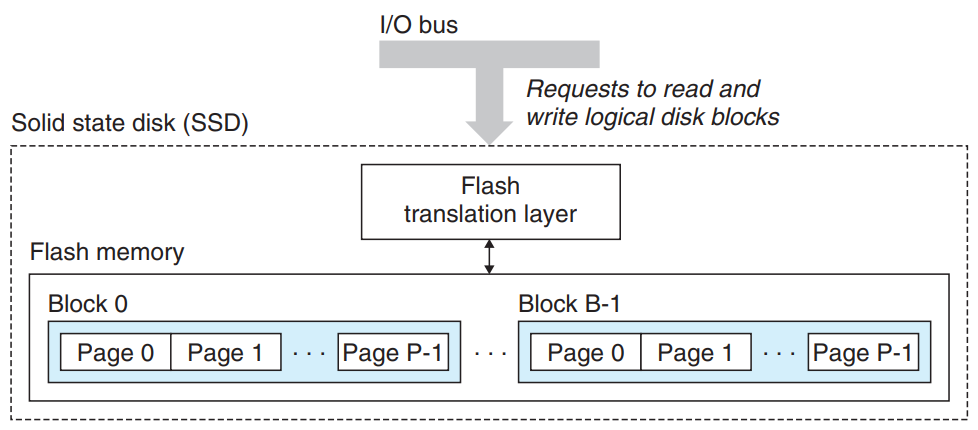
- SSD’s component
- one or more flash memory chips
Flash memory chips are similar with the mechanical drive in a conventional rotating disk.
Flash memory consists of a sequence of B blocks, where each block consists of P pages.
- flash translation layer disk controller
Flash translation layer translates requests for logical blocks into accesses of the physical device.
- one or more flash memory chips
- Writing of SSD
SSD’s data are read and written in units of pages.
A page can be written only after the block to which it belongs has been erased. Once a block is erased, each page in the block can be written once with no further erasing.
If a write operation attempts to modify a page p, then any pages in the same block with useful data must be copied to a new block before erasure.
⇒ Random writing is slower than random reading.
- Advantages of SSD over rotating disks
- SSDs have much faster random access times.
- SSDs use less power.
- SSDs are more rugged.
- Disadvantages of SSD
- SSDs have potential to wear out - A block wears out after roughly 100,000 repeated writes.
⇒ Wear-leveling logic in the flash translation layer attempts to maximize the lifetime of each block by spreading erasures across the blocks.
- SSDs are about 30 times more expensive per byte than rotating disks.
- SSDs have potential to wear out - A block wears out after roughly 100,000 repeated writes.
- SSD’s component
Storage Technology Trends
- Different storage technologies have different price and performance trade-offs. - Fast storage is always more expensive than slower storage.
- The price and performance properties of different storage technologies are changing at dramatically different rates.
- DRAM and disk performance are lagging behind CPU performance → Modern computers make heavy use of SRAM-based caches to try to bridge the processor-memory gap.
6.2 Locality
6.2 Locality
Meaning of Locality
Programs with good locality tend to reference data items that are near other recently referenced data items or that were recently referenced themselves.
In a program of good temporal locality, a memory location referenced once is likely to be referenced again multiple times in the near future.
In a program of good spatial locality, if a memory location is referenced once, then the program is likely to reference a nearby memory location in the near future.
Programs with good locality run faster
In general, programs with good locality run faster than programs with poor locality.
All levels of modern computer systems are designed to exploit locality :
- Hardware level : Introducing cache memories improves the speed of main memory access.
- Operating system : OS uses the main memory as a cache for most recently referenced chunks of virtual address space or most recently used disk blocks.
- Application programs (example : Web browsers) : Web browsers caches recently referenced documents on a local disk.
Locality of References to Program Data :
sumvecint sumvec(int v[N]){ int i, sum = 0; for(i = 0; i < N; ++i) sum += v[i]; return sum; }- Locality of each variables
sum: referenced once in each loop iteration → good temporal locality, no spatial localityv[i]: each elements are referenced only once, but read sequentially → poor temporal locality, good spatial localitysumvechas either good spatial or temporal locality with respect to each variable in the loop body →sumvecenjoys good locality.- stride-k reference pattern
Visiting every kth element of a contiguous vector is called a stride-k reference pattern. (example :
sumvechave a stride-1 reference pattern.)In general, as the stride increases, the spatial locality decreases.
Locality of Instruction Fetches
Program instructions are stored in memory and must be fetched by the CPU → we can also evaluate the locality of a program.
For example,
sumvec's instructions inforloop are executed multiple times, in sequential memory order → good spatial, temporal locality
6.3 The Memory Hierarchy
6.3 The Memory Hierarchy
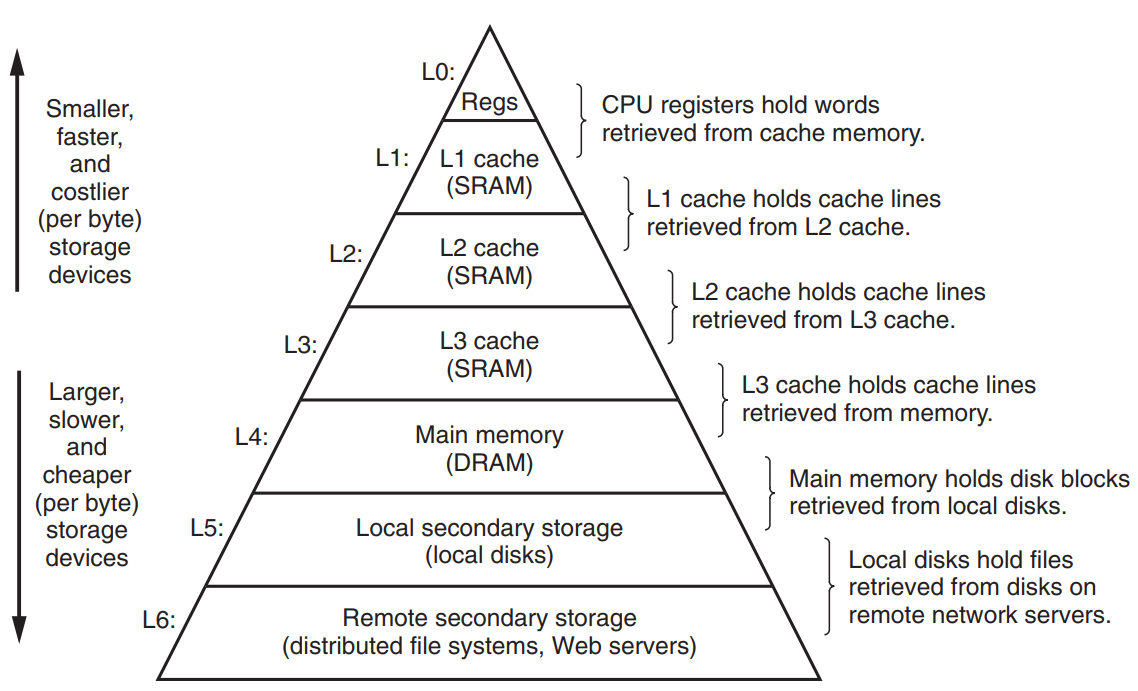
Memory hierarchy is introduced to make storage technology and computer software complement each other :
- Storage technology : Faster technologies cost more per byte and have less capacity.
- Computer software : Well-written programs tend to exhibit good locality.
Caching in the Memory Hierarchy
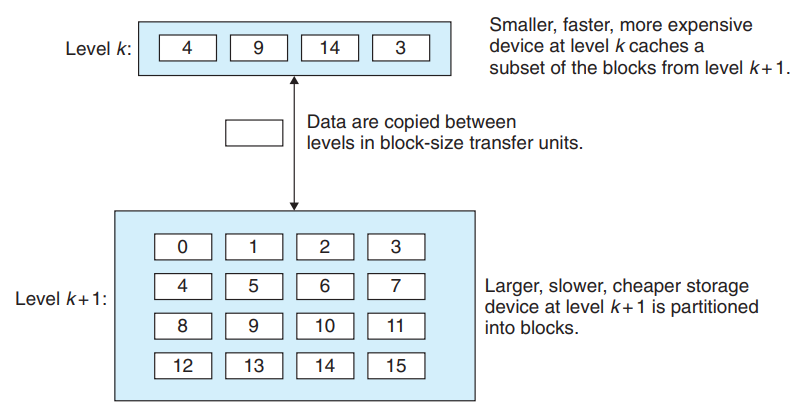
In memory hierarchy, for each k, the faster and smaller storage device at level k serves as a cache for the larger and slower storage device at level k + 1.
The storage at level k+1 is partitioned into contiguous chunks of data objects called blocks, while the storage at level k is partitioned into a smaller set of blocks that are the same size as the blocks at level k+1.
At any point, the cache at level k contains copies of a subset of the blocks from level k+1. Data are always copied back and forth between level k and level k + 1 in block-size transfer units.
While the block size is fixed between any particular pair of adjacent levels in the hierarchy, other pairs of levels can have different block sizes. Devices lower in the hierarchy have longer access times, and thus tend to use larger block sizes to amortize these longer access times.
(example : L0 ↔ L1 : word-size, L1 ↔ L2 : tens of bytes, L5 ↔ L4 : hundreds or thousands of bytes)
- Cache Hits
When a program needs a particular data object d from level k + 1, it first looks for d in one of the blocks stored at level k. If d happens to be cached at level k, then we have a cache hit.
- Cache Misses
If d is not cached at level k, then we have a cache miss - the cache at level k fetches the block containing d from the cache at level k + 1, possibly overwriting an existing block if the level k cache is already full (evicting).
The decision about which block to replace is governed by the cache’s replacement policy.
(example : random replacement poilcy choose a random victim block, and least recently used (LRU) replacement policy choose the block that was last accessed the furthest in the past.)
- Kinds of Cache Misses
- Cold Miss
An empty cache is referred to as a cold cache - Cache misses due to empty cache are called cold misses.
- Conflict Miss
Cache at level k’s placement policy determines where to place the block it has retrieved from level k + 1.
Allowing any block from level k + 1 to be stored in any block at level k is too expensive for hardware caches → Hardware caches typically implement a policy that restricts a particular block at level k + 1 to a small subset of the blocks at level k. (example : A block i at level k + 1 must be placed in block (i mod 4) at level k.)
Conflict miss occurs when the cache is large enough to hold the referenced data objects, but because they map to the same cache block, the cache keeps missing.
- Capacity Miss
Programs often run as a sequence of phases where each phase accesses some reasonably constant set of cache blocks. (example : loops) - This set of blocks is called the working set of the phase.
When the size of the working set exceeds the size of the cache, the cache will experience what are known as capacity misses.
- Cache Management
At each level, some form of logic must manage the cache - partitioning the cache storage into blocks, transferring blocks between different levels, deciding when there are hits and misses, and dealing with them. The logic that manages the cache can be hardware, software, or a combination of the two :
- Compiler → register file : compiler decides when to issue loads when there are misses, and determines which register to store the data in.
- Hardware → L1, L2, L3
- Caching and Locality
- Caching exploits temporal locality
Once a data object has been copied into the cache on the first miss, we can expect a number of subsequent hits on that object. → These subsequent hits can be served much faster than the original miss.
- Caching exploits spatial locality
Blocks usually contain multiple data objects → The cost of copying a block after a miss will be amortized by subsequent references to other objects within that block.
6.4 Cache Memories
6.4 Cache Memories
Generic Cache Memory Organization
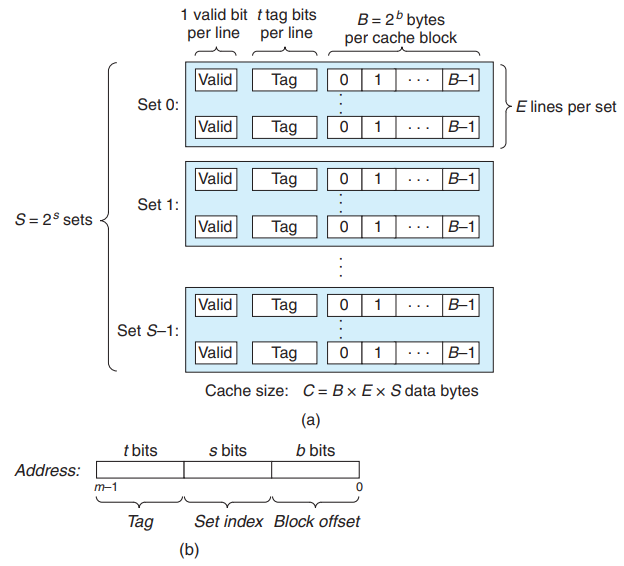
In a system where each memory address has m bits that form unique addresses, a cache is organized as an array of cache sets. Each set consists of E cache lines.
Each line consists of :
- A data block of bytes
- A valid bit that indicates whether or not the line contains meaningful information
- tag bits that uniquely identify the block stored in the cache line.
A cache’s organization can be characterized by the tuple (S, E, B, m). The capacity of a cache, C, is stated in terms of the aggregate size of all the blocks → .
Cache is organized so that it can find the requested word by simply inspecting the bits of the address, similar to a hash table.
m address bits are partitioned into three fields :
- s set index bits form an index to the array of S sets - they tell us which set the word must be stored in when interpreted as an unsigned integer.
- t tag bits tell us which line in the set contains the word : A line in the set contains the word ↔ the valid bit is set && the tag bits in the line == the tag bits in the address
- b block offset bits give us the offset of the word in the B-byte data block.
Direct-Mapped Caches
Direct-Mapped cache refers to a cache with exactly one line per set. (E=1)
- The process that a cache determines whether a request is a hit or a miss and then extracts the requested word w :
- Set Selection in Direct-Mapped Caches
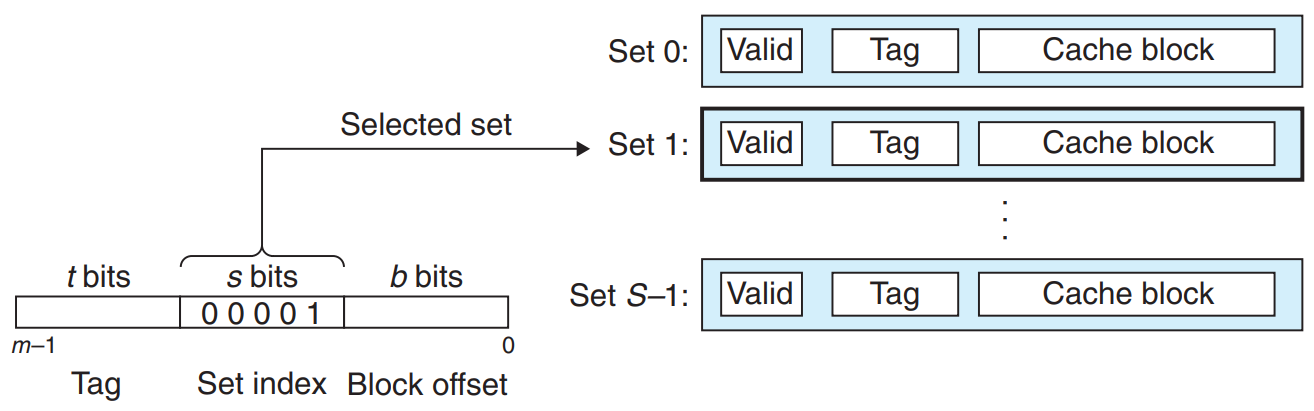
The cache extracts the s set index bits from the middle of the address for w. These bits are interpreted as an unsigned integer that corresponds to a set number.
- Line Matching in Direct-Mapped Caches
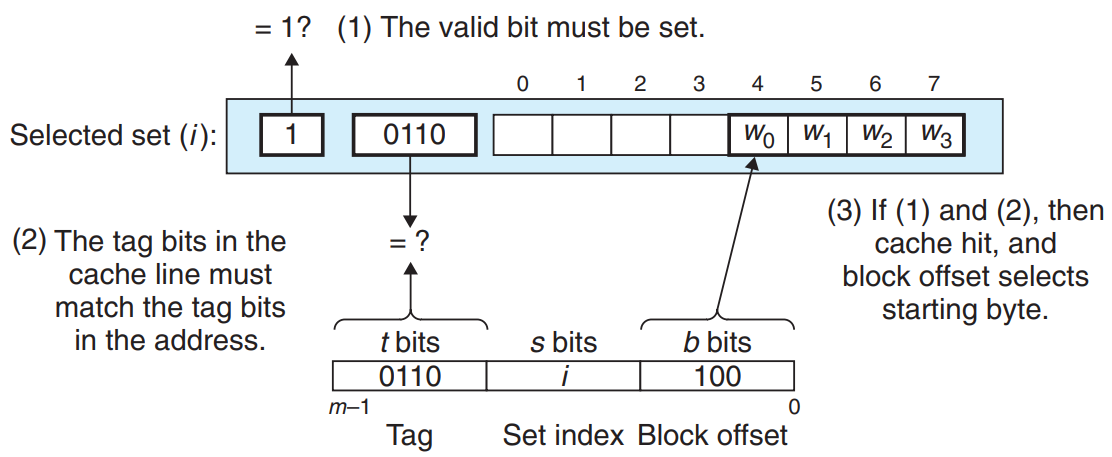
Determining if a copy of the word w is stored in one of the cache lines : A copy of w is contained in the line ↔ the valid bit is set && the tag in the cache line == the tag in the address of w
- Word Selection in Direct-Mapped Caches
The block offset bits provide us with the offset of the first byte in the desired word → We can determine where the desired word starts in the block.
- Line Replacement on Misses in Direct-Mapped Caches
If the set is full of valid cache lines, one of the existing lines must be evicted - For a direct-mapped cache, the replacement is trivial: the current line is replaced by the new line.
- Example Direct-Mapped Cache :
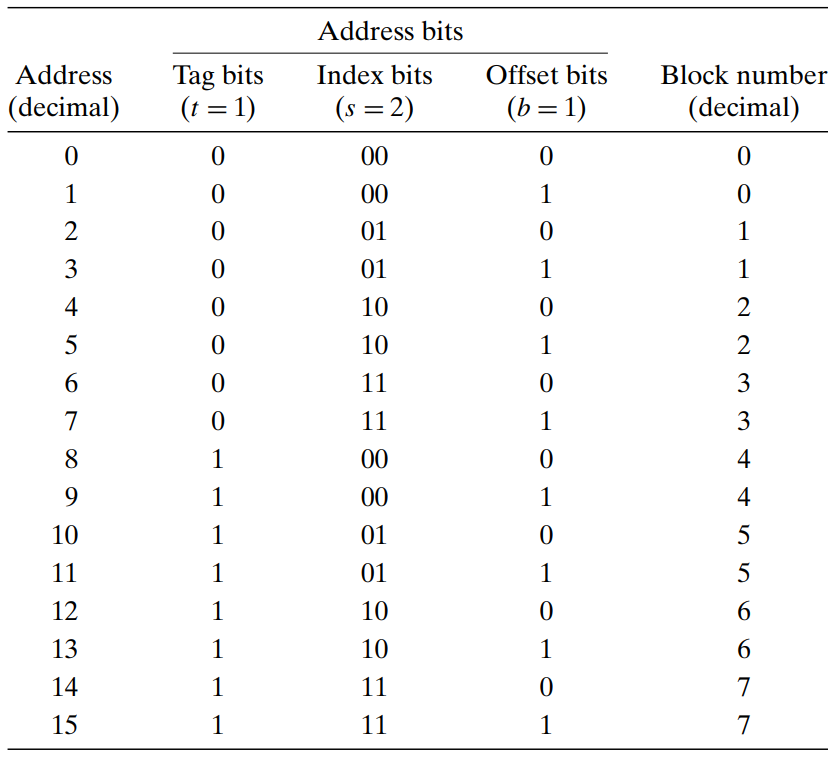
The concatenation of the tag and index bits uniquely identifies each block in memory. (example : block 0 consists of addresses 0 and 1, block 1 consists of addresses 2 and 3, and so on.)
There are 8 memory blocks but only 4 cache sets → multiple blocks map to the same cache set. (example : blocks 0 and 4 both map to set 0.)
Blocks that map to the same cache set are uniquely identified by the tag. (example : block 0 has a tag bit of 0 while block 4 has a tag bit of 1.)
- Conflict Misses in Direct-Mapped Caches :
dotprodfloat dotprod(float x[8], float y[8]){ float sum = 0.0; int i; for(i = 0; i < 8; i++) sum += x[i] * y[i]; return sum; }This function has good spatial locality → we might expect it to enjoy a good number of cache hits. However, this is not always true.
Suppose that floats are 4 bytes, that
xis loaded into the 32 bytes of contiguous memory starting at address 0, that y starts immediately afterxat address 32, that a block is 16 bytes and that the cache consists of 2 sets, for a total cache size of 32 bytes. Given these assumptions, eachx[i]andy[i]will map to the identical cache set :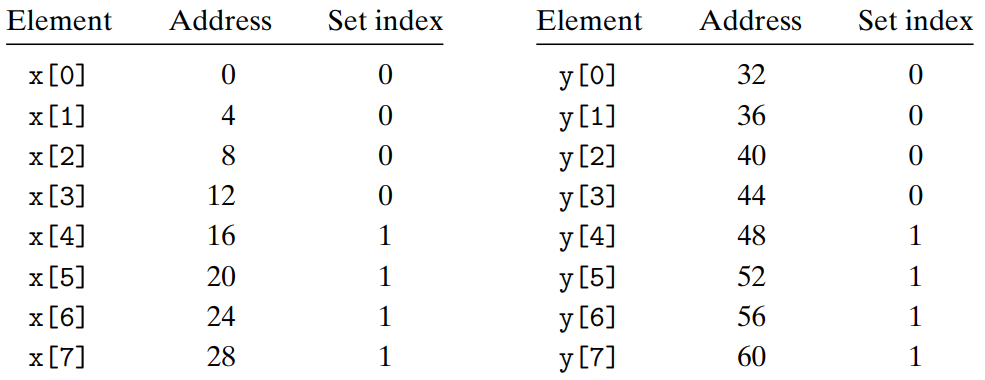
At run time, the first reference to
x[0]leads to a cache miss that causes the block containingx[0]~x[3]to be loaded into set 0. The next reference toy[0]leads to another miss that causes they[0]~y[3]block to be copied into set 0, overwriting the values ofxthat were copied in by the previous reference. During the next iteration, the reference tox[1]misses, which causes thex[0]~x[3]block to be loaded back into set 0, overwriting they[0]~y[3]block. → Thrashing Conflict Miss (A cache is repeatedly loading and evicting the same sets of cache blocks.)Even though the program has good spatial locality and we have room in the cache to hold the blocks, each reference can result in a conflict miss because the blocks map to the same cache set.
- Solution : Put B bytes of padding at the end of each array.
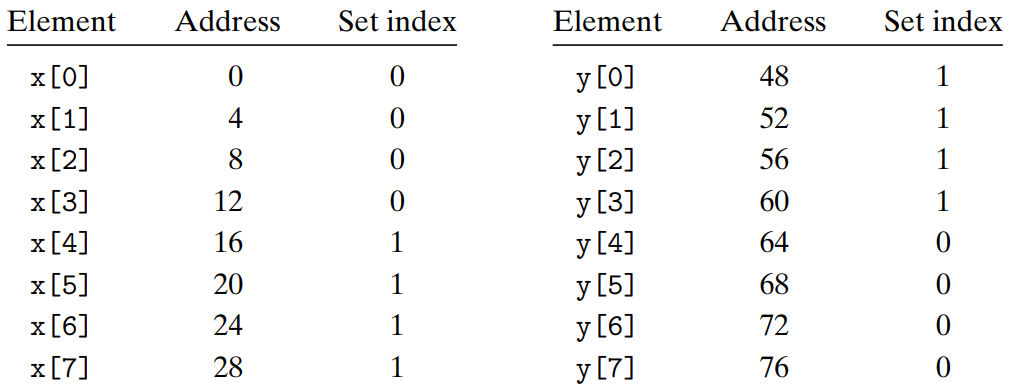
If we define
xasfloat x[12], the mapping of array elements to sets change as above. →x[i]andy[i]now map to different sets, which eliminates the thrashing conflict misses.
- The process that a cache determines whether a request is a hit or a miss and then extracts the requested word w :
Set Associative Caches
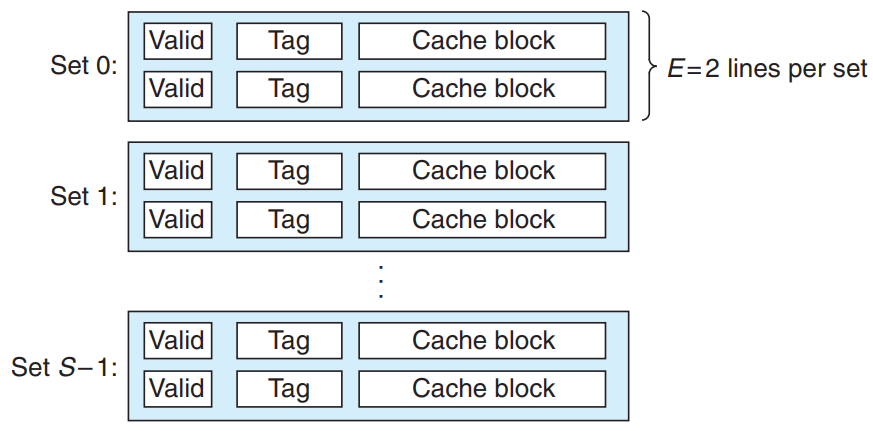
Set associative cache is a cache that each set holds more than one cache line. () → Can solve the problem with conflict misses in direct-mapped caches.
- Set Selection in Set Associative Caches
Set selection is identical to a direct-mapped cache.
- Line Matching and Word Selection in Set Associative Caches
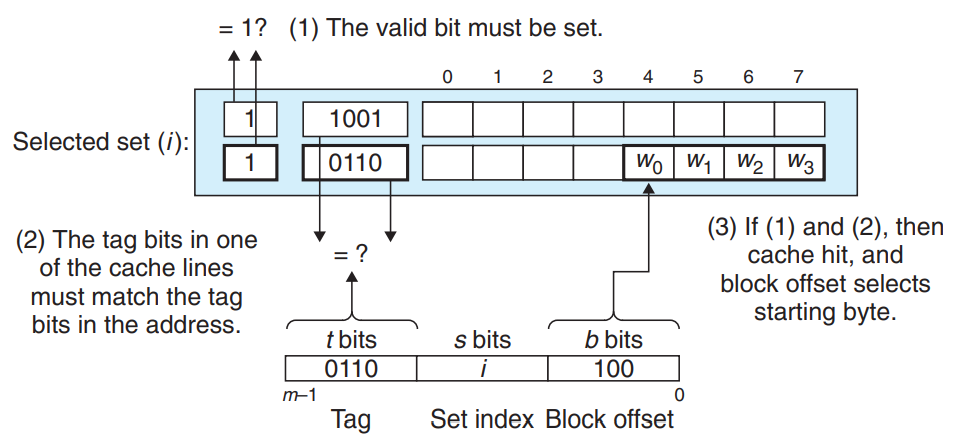
The cache must search each line in the set for a valid line whose tag matches the tag in the address. → If the cache finds such a line, we have a hit. → The block offset selects a word from the block.
- Line Replacement on Misses in Set Associative Caches
If we have a miss, we have to evict some line, and retrieve the requested block. Some sophisticated replacement policy draw on the principle of locality to try to minimize the probability that the replaced line will be referenced in the near future.
- Least frequently used (LFU) policy : replace the line that has been referenced the fewest times over some past time window.
- Least recently used (LRU) policy : replace the line that was last accessed the furthest in the past.
- Set Selection in Set Associative Caches
Fully Associative Caches
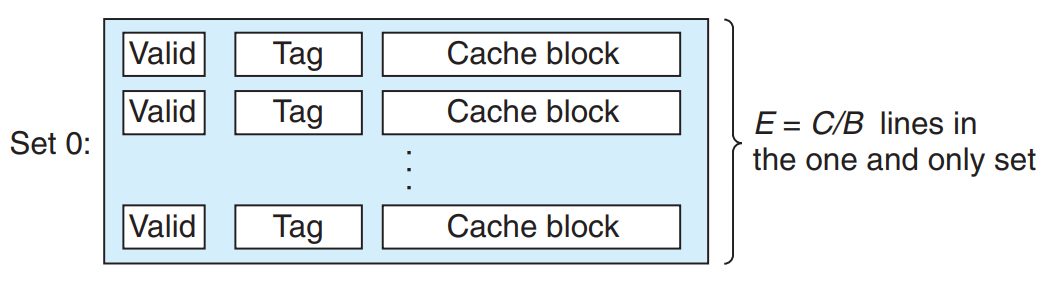
A fully associative cache consists of a single set that contains all of the cache lines. ()
- Set Selection in Fully Associative Caches
Set selection in fully associative cache is trivial because there is only one set. → There are no set index bits in the address, which is partitioned into only a tag and a block offset.
- Line Matching and Word Selection in Fully Associative Caches
Line matching and word selection in fully associative cache work the same as with a set associative cache.
The cache circuitry must search for many matching tags in parallel → It’s difficult and expensive to build an both large and fast associative cache. → Fully associative caches are only appropriate for small caches.
- Set Selection in Fully Associative Caches
Issues with Writes
- Write Hit
When we write a word w that is already cached (write hit), first the cache updates its copy of w. Then, cache can do 2 things about updating the copy of w in the next lower level cache :
- Write-through
After updating its copy of w in the cache, write-through immediately writes w’s cache block to the next lower level.
Advantage : Being simple
Disadvantage : causing bus traffic with every write.
- Write-back
Write-back defers the update as long as possible by writing the updated block to the next lower level only when it is evicted from the cache by the replacement algorithm.
Advantage : Reducing the amount of bus traffic.
Disadvantage : Additional complexity - the cache must maintain an additional dirty bit for each cache line that indicates whether or not the cache block has been modified.
- Write-through
- Write Miss
- Write-allocate
Write-allocate loads the corresponding block from the next lower level into the cache and then updates the cache block.
Write-back caches are typically write-allocate.
Advantage : Can exploit spatial locality of writes
Disadvantage : Every miss results in a block transfer from the next lower level to the cache.
- No-write-allocate
No-write-allocate bypasses the cache and writes the word directly to the next lower level.
Write-through caches are typically no-write-allocate.
- Write-allocate
To write cache-friendly programs, assume the write-back, write-allocate caches. - Modern computers generally uses write-back caches at all levels, and it is symmetric to the way reads are handled, in that it tries to exploit locality.
- Write Hit
Anatomy of a Real Cache Hierarchy
- i-cache : A cache that holds instructions only.
- d-cache : A cache that holds program data only.
- unified-cache : A cache that holds both instructions and data.
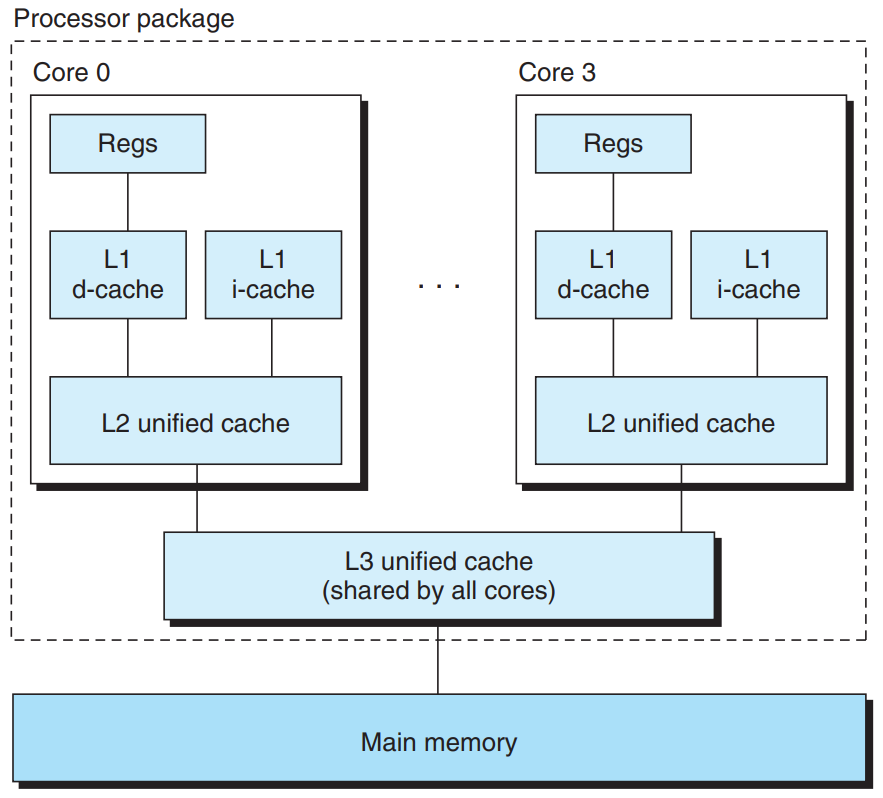
Modern processors include separate i-caches and d-caches :
- The two caches are often optimized to different access patterns and can have different block sizes, associativities, and capacities.
- Having separate caches ensures that data accesses do not create conflict misses with instruction accesses, and vice versa, at the cost of a potential increase in capacity misses.
Performance Impact of cache Parameters
Cache performance is evaluated with a number of metrics:
- Miss rate :
- Hit rate : 1 - miss rate
- Hit time : The time to deliver a word in the cache to the CPU, including the time for set selection, line identification, and word selection.
- Miss penalty : Any additional time required because of a miss.
Some qualitative trade-offs in optimizing the cost and performance of cache memories :
- Impact of Cache Size
Larger cache → Increased hit rate
Larger cache → Harder to make memories run faster → Increased hit time
⇒ An L1 cache is smaller than an L2 cache, and an L2 cache is smaller than an L3 cache.
- Impact of Block Size
Larger blocks → Can exploit spatial locality that might exist in a program → Increased hit rate
Larger blocks → For a given cache size, a smaller number of cache lines → Decreased hit rate in programs with more temporal locality than spatial locality
Larger blocks → Larger transfer times → Higher miss penalty
- Impact of Associativity
Higher associativity → Decreased vulnerability to thrashing conflict misses
Higher associativity → Requires more tag bits per line, additional LRU state bits per line, and additional control logic → Expensive to implement and hard to make fast
Higher associativity → Increased complexity → Increased hit time & miss penalty (the complexity of choosing a victim line also increases.)
⇒ Modern systems would take smaller associativity for L1 caches, where the miss penalty is only a few cycles, and a larger associativity for the lower levels, where the miss penalty is higher.
- Impact of Write Strategy
- Write-through caches
- Simpler to implement
- Can use a write buffer that works independently of the cache to update memory
- Read misses are less expensive because they do not trigger a memory write. → I don’t understand this part...🙄
- Write-back caches
- Fewer transfers → More bandwidth to memory for I/O devices that perform DMA.
- Fewer transfers → Caches further down the hierarchy, where the transfer time is high, are more likely to use write-back than write-through.
- Write-through caches
6.5 Writing Cache-Friendly Code
6.5 Writing Cache-Friendly Code
Cache-friendly code is a code that has good locality. Here is the basic approach to write cache-friendly code :
- Focus on the inner loops of the core functions, and ignore the rest.
- Minimize the number of cache misses in each inner loop.
- Repeated references to local variables are good because the compiler can cache them in the register file. (temporal locality)
- Stride-1 reference patterns are good because caches at all levels store data as contiguous blocks. (spatial locality)
If a cache has a block size of B bytes, then a stride-k reference pattern results in an average of misses per loop iteration.
6.6 Putting It Together: The Impact of Caches on Program Performance
6.6 Putting It Together: The Impact of Caches on Program Performance
The Memory Mountain
Write a program that issued a sequence of read requests from a tight program loop, then measure the read throughput → We can get some insight into the performance of the memory system for that particular sequence of reads.
long data[MAXELEMS]; /* The global array we'll be traversing */ /* test - Iterate over first "elems" elements of array "data" with stride of "stride", using 4 x 4 loop unrolling. */ int test(int elems, int stride){ long i, sx2 = stride * 2, sx3 = stride * 3, sx4 = stride * 4; long acc0 = 0, acc1 = 0, acc2 = 0, acc3 = 0; long length = elems; long limit = length - sx4; /* Combine 4 elements at a time */ for(i = 0; i < limit; i += sx4) { acc0 = acc0 + data[i]; acc1 = acc1 + data[i + stride]; acc2 = acc2 + data[i + sx2]; acc3 = acc3 + data[i + sx3]; } /* Finish any remaining elements */ for(; i < length; ++i){ acc0 = acc0 + data[i]; } return ((acc0 + acc1) + (acc2 + acc3)); } /* run - Run test(elems, stride) and return read throughput. "size" is in bytes, "stride" is in array elements, and Mhz is CPU clock frequency in Mhz. */ double run(int size, int stride, double Mhz){ double cycles; int elems = size / sizeof(double); test(elems, stride); /* Warm up the cache */ cycles = fcyc2(test, elems, stride, 0); /* Call test(elems, stride) */ return (size / stride) / (cycles / Mhz); /* Convert cycles to MB/s */ }The
sizeandstridearguments to therunfunction allow us to control the degree of temporal and spatial locality in the resulting read sequence - Smaller values ofsizeresult in better temporal locality, and smaller values ofstrideresult in better spatial locality. If we call therunrepeatedly with different values ofsizeandstride, we can get a two-dimensional function of read throughput versus temporal and spatial locality : A memory mountain.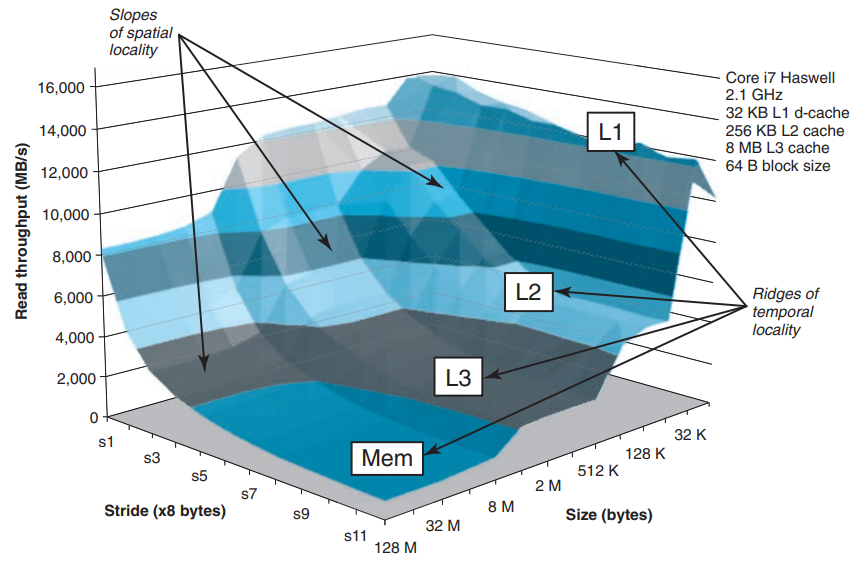
A memory mountain for an Intel Core i7 Haswell system. The performance of the memory system is not characterized by a single number. - It is a mountain of temporal and spatial locality whose elevations can vary by over an order of magnitude.
Rearranging Loops to Increase Spatial Locality
A matrix multiply function with several minor code changes :

Even though each version performs total operations and an identical number of adds and multiplies, there are differences in the number of accesses and the locality.
- Version ijk & Version jik : class AB
ijk & jik reference arrays A and B in their innermost loop.
Each iteration performs two loads and no store operation.
The inner loops of the class AB scans a row of array A with a stride of 1. → Each cache block holds four 8-byte words → miss rate for A is 0.25 misses per iteration.
The inner loops of the class AB scans a column of B with a stride of n. → n is large, each access of array B results in a miss → miss rate for B is 1 misses per iteration.
⇒ total of 1.25 misses per iteration.
- Version jki & Version kji : class AC
jki & kji reference arrays A and C in their innermost loop.
Each iteration performs two loads and one store operation.
The inner loop scans the columns of A and C with a stride of n. → two misses per iteration.
- Version kij & Version ijk : class BC
kij & ikj reference arrays B and C in their innermost loop.
Each iteration performs two loads and one store operation.
The inner loop scans the rows of B and C with a stride of 1. → 0.5 misses per iteration.
- Performance of different versions of matrix multiply
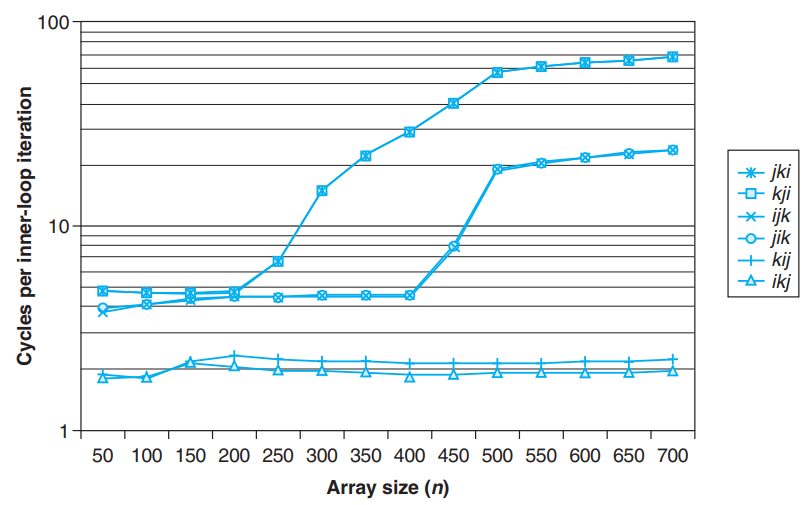
- Pairs of versions with the same number of memory references and misses per iteration have almost identical measured performance.
- Miss rate is a better predictor of performance than the total number of memory accesses. (example : BC vs. AB)
- For large values of n, the performance of class BC is constant - the prefetching hardware is smart enough to recognize the stride-1 access pattern, and fast enough to keep up with memory accesses in the tight inner loop.
(A hardware prefetching mechanism automatically identifies stride-1 reference patterns and attempts to fetch those blocks into the cache before they are accessed.)
Exploiting Locality in Your Programs
- Focus your attention on the inner loops, where the bulk of the computations and memory accesses occur.
- Try to maximize the spatial locality in your programs by reading data objects with stride 1.
- Try to maximize the temporal locality in your programs by using a data object as often as possible once it has been read from memory.
Leave a comment