CS:APP Chapter 12 Summary 🧙
Recently, I’ve been studying CS:APP - I’m posting my own summary of chapter 12 that I wrote up using Notion.
12.1 Concurrent Programming with Processes
12.1 Concurrent Programming with Processes
We can build a concurrent program with processes, using familiar functions such as fork, exec, and waitpid.
(example : accepting client connection requests in the parent and then creating a new child process to service each new client.)
#include "csapp.h"
void echo(int connfd);
void sigchld_handler(int sig) {
while (waitpid(-1, 0, WNOHANG) > 0) ;
return;
}
int main(int argc, char **argv) {
int listenfd, connfd;
socklen_t clientlen;
sockaddr_storage clientaddr;
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(0);
}
Signal(SIGCHLD, sigchld_handler);
listenfd = Open_listenfd(argv[1]);
while (1) {
clientlen = sizeof(sockaddr_storage);
connfd = Accept(listenfd, (SA *) &clientaddr, &clientlen);
if (Fork() == 0) {
Close(listenfd); /* Child closes its listening socket */
echo(connfd); /* Child services client */
Close(connfd); /* Child closes connection with client */
exit(0); /* Child exits */
}
Close(connfd); /* Parent closes connected socket */
}
}- After accepting the connection request, the child closes its copy of listening descriptor, and the parent closes its copy of connected descriptor, since they are no longer needed.
- We must include a SIGCHLD handler that reaps zombie children. Since Linux signals are not queued, the handler must be able to reap multiple zombie children.
- The parent and the child must close their respective copies of
connfdrespectively.
- Pros and Cons of Concurrent Programming Using Processes
- Pros - It’s impossible for one process to overwrite the virtual memory of another process.
- Cons - It’s difficult for processes to share state information. To share information, they must use explicit IPC mechanisms.
- Cons - Process-based designs tend to be slower because the overhead for process control and IPC is high.
12.2 Concurrent Programming with I/O Multiplexing
12.2 Concurrent Programming with I/O Multiplexing
I/O Multiplexing
- I/O multiplexing’s basic idea is to use the
selectfunction to ask the kernel to suspend the process, returning control to the application only after one or more I/O events have occurred, as in the following examples:- Return when any descriptor in the set {0, 4} is ready for reading.
- Return when any descriptor in the set {1, 2, 7} is ready for writing.
- Time out if 152.13 seconds have elapsed waiting for an I/O event to occur.
Select- We will only discuss the first scenario : waiting for a set of descriptor to be ready for reading.
#include <sys/select.h> int select(int n, fd_set *fdset, NULL, NULL, NULL); /* Macros for manipulating descriptor sets */ FD_ZERO(fd_set *fdset); FD_CLR(int fd, fd_set *fdset); FD_SET(int fd, fd_set *fdset); FD_ISSET(int fd, fd_set *fdset);- Descriptor set
fd_setis a bit vector of sizen: - Each bit corresponds to descriptor k. Descriptor k is a member of the set if and only if .
selecttakes 2 inputs:fdsetcalled the read set, and the cardinality (n) of the read set.
selectblocks until at least one descriptor in the read set is ready for reading (= a request to read 1 byte from that descriptor wouldn’t block).
selectmodifies the argumentfdsetto indicate a subset of the read set called the ready set, consisting of the descriptors in the read set that are ready for reading.
- Example Code - An iterative echo server that uses I/O multiplexing
#include "csapp.h" void echo(int connfd); void command(void); int main(int argc, char **argv) { int listenfd, connfd; socklen_t clientlen; struct sockaddr_storage clientaddr; fd_set read_set, ready_set; if (argc != 2) { fprintf(stderr, "usage: %s <port>\n", argv[0]); exit(0); } listenfd = Open_listenfd(argv[1]); FD_ZERO(&read_set); /* Clear read set */ FD_SET(STDIN_FILENO, &read_set); /* Add stdin to read set */ FD_SET(listenfd, &read_set); /* Add listenfd to read set */ while (1) { ready_set = read_set; Select(listenfd+1, &ready_set, NULL, NULL, NULL); if (FD_ISSET(STDIN_FILENO, &ready_set)) command(); /* Read command line from stdin */ if (FD_ISSET(listenfd, &ready_set)) { clientlen = sizeof(struct sockaddr_storage); connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen); echo(connfd); /* Echo client input until EOF */ Close(connfd); } } } void command(void) { char buf[MAXLINE]; if (!Fgets(buf, MAXLINE, stdin)) exit(0); /* EOF */ printf("%s", buf); /* Process the input command */ }- In the infinite server loop, instead of calling the
acceptfunction, we call theselectwhich blocks until either the listening descriptor or standard input is ready for reading.
- Once this program connects to a client, it continues echoing input lines until the client closes its end of the connection.
→ If you type a command to standard input, you won’t get a response until the server is finished with the client.
→ Multiplex at a finer granularity, echoing at most one text line each time through the server loop.
- In the infinite server loop, instead of calling the
- I/O multiplexing’s basic idea is to use the
A Concurrent Event-Driven Server Based on I/O Multiplexing
I/O multiplexing can be used as the basis for concurrent event-driven programs, which models logical flows as state machines.
- State Machine
- A state machine is a collection of states, input events, and transitions that map (input state, input event) pair to an output state.
- Each input event triggers a transition from the current state to the next state.
- Concurrent server based on I/O multiplexing
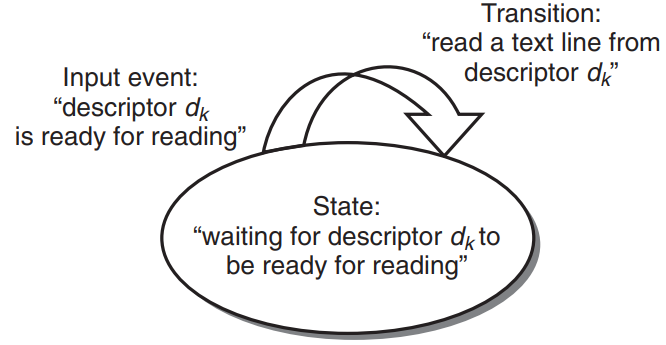
- For each new client k, the server creates a new state machine and associates it with connected descriptor .
- The multiplexing to detect the occurrence of input events. - As each connected descriptor becomes ready for reading, the server executes the transition - reading and echoing a text line from the descriptor.
- Example Code - Concurrent echo server based on I/O multiplexing
main#include "csapp.h" typdef struct { /* Represents a pool of connected descriptors */ int maxfd; /* Largest descriptor in read_set */ fd_set read_set; /* Set of all active descriptors */ fd_set ready_set; /* Subset of descriptor ready for reading */ int nready; /* Number of ready descriptors from select */ int maxi; /* High water index into client array */ int clientfd[FD_SETSIZE]; /* Set of active descriptors */ rio_t clientrio[FD_SETSIZE]; /* Set of active read buffers */ } pool; int byte_cnt = 0; /* Counts total bytes received by server */ int main(int argc, char **argv) { int listenfd, connfd; socklen_t clientlen; struct sockaddr_storage clientaddr; static pool pool; if (argc != 2) { fprintf(stderr, "usage: %s <port>\n", argv[0]); exit(0); } listenfd = Open_listenfd(argv[1]); init_pool(listenfd, &pool); while(1) { /* Wait for listening/connected descriptor(s) to become ready */ pool.ready_set = pool.read_set; pool.nready = Select(pool.maxfd+1, &pool.ready_set, NULL, NULL, NULL); /* If listening descriptor ready, add new client to pool */ if (FD_ISSET(listenfd, &pool.ready_set)) { clientlen = sizeof(struct sockaddr_storage); connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen); add_client(connfd, &pool); } /* Echo a text line from each ready connected descriptor */ check_clients(&pool); } }
init_poolvoid init_pool(int listenfd, pool *p) { /* Initially, there are no connected descriptors */ int i; p->maxi = -1; for (i=0; i< FD_SETSIZE; i++) p->clientfd[i] = -1; /* Initially, listenfd is only member of select read set */ p->maxfd = listenfd; FD_ZERO(&p->read_set); FD_SET(listenfd, &p->read_set); }clientfdrepresents a set of connected descriptors, with the integer -1 denoting an available slot.
add_clientvoid add_client(int connfd, pool *p) { int i; p->nready--; for (i = 0; i < FD_SETSIZE; i++) /* Find an available slot */ if (p->clientfd[i] < 0) { /* Add connected descriptor to the pool */ p->clientfd[i] = connfd; Rio_readinitb(&p->clientrio[i], connfd); /* Add the descriptor to descriptor set */ FD_SET(connfd, &p->read_set); /* Update max descriptor and pool high water mark */ if (connfd > p->maxfd) p->maxfd = connfd; if (i > p->maxi) p->maxi = i; break; } if (i == FD_SETSIZE) /* Couldn't find an empty slot */ app_error("add_client error: Too many clients"); }p->nready--:nreadyincludes listening descriptor as a descriptor ready for reading, which is actually not.
check_clientsvoid check_clients(pool *p) { int i, connfd, n; char buf[MAXLINE]; rio_t rio; for (i = 0; (i <= p->maxi) && (p->nready > 0); i++) { connfd = p->clientfd[i]; rio = p->clientrio[i]; /* If the descriptor is ready, echo text line from it */ if ((connfd > 0) && (FD_ISSET(connfd, &p->ready_set))) { p->nready--; if ((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0) { byte_cnt += n; printf("Server received %d (%d total) bytes on fd %d\n", n, byte_cnt, connfd); Rio_writen(connfd, buf, n); } /* EOF detected, remove descriptor from pool */ else { Close(connfd); FD_CLR(connfd, &p->read_set); p->clientfd[i] = -1; } } } }check_clientsechoes a text line from each ready connected descriptor.
- If we detect EOF because the client has closed its end of the connection, we close our end of the connection and remove the descriptor from the pool.
- In terms of the finite state model,
selectdetects input events, and theadd_clientcreates a new state machine.check_clientsperforms state transitions and deletes the state machine when the client has finished sending text lines.
- State Machine
Pros and Cons of I/O Multiplexing
- Pros of I/O Multiplexing
- Event-driven designs give programmers more control over the behavior of their programs than process-based designs.
- An event-driven server based on I/O multiplexing runs in the context of a single process.
- → every logical flow has access to the entire address space of the process. → Easy to share data between flows
- → You can debug your concurrent server as you would any sequential program.
- Event-driven designs are often more efficient than process-based designs because they don’t require a process context switch to schedule a new flow.
- Cons of I/O Multiplexing
- Coding complexity increases as the granularity of the concurrency decreases.
- granularity = # of instructions that each logical flow executes per time slice. (example : # of instructions required to read an entire text line)
- Can’t fully utilize multi-core processors.
- Coding complexity increases as the granularity of the concurrency decreases.
- Pros of I/O Multiplexing
12.3 Concurrent Programming with Threads
12.3 Concurrent Programming with Threads
Thread
A thread is a logical flow that runs in the context of a process.
- The threads are scheduled automatically by the kernel.
- Each thread has its own thread context - thread ID (TID), stack, stack pointer, program counter, general-purpose registers, and condition codes.
- All threads running in a process share the entire VAS of that process.
Thread Execution Model
- Each process begins life as a single thread called the main thread, which creates a peer thread.
- Control passes to the peer thread via a context switch, either because the main thread executes a slow system call or because it is interrupted by the system’s interval timer.
- Thread execution vs. processes
- A thread context is much smaller → a thread context switch is faster.
- The threads are not organized in a rigid parent-child hierarchy - They form a pool of peers, independent of which threads were created by which other threads.
→ A thread can kill any of its peers or wait for any of its peers to terminate.
- Each peer can read and write the same shared data.
Posix Threads - Creating Threads
Posix threads (Pthreads) is a standard interface for manipulating threads from C programs.
#include <pthread.h> typedef void *(func)(void *); int pthread_create(pthread_t *tid, pthread_attr_t *attr, func *f, void *arg); pthread_t pthread_self(void);pthread_createcreates a new thread and runs the thread routinefin the context of the new thread and with an input argument ofarg.
- Each thread routine takes as input a single generic pointer and returns a generic pointer. → Put the arguments into a structure to pass multiple arguments or let the routine return multiple arguments.
- When
pthread_createreturns, argumenttidcontains the ID of the newly created thread.
- The new thread can determine its own thread ID by calling the
pthread_self.
Posix Threads - Terminating Threads
A thread terminates in one of the following ways:
- The thread terminates implicitly when its top-level thread routine returns.
- The thread terminates explicitly by calling the
pthread_exit.#include <pthread.h> void pthread_exit(void *thread_return);If the main thread calls
pthread_exit, it waits for all other peer threads to terminate and then terminates the main thread and the entire process with a return value ofthread_return.
- The thread calls the Linux
exitfunction, which terminates the process and all threads associated with the process.
- The thread calls the
pthread_cancelwith the ID of the current thread.#include <pthread.h> int pthread_cancel(pthread_t tid);
Posix Threads - Reaping Terminated Threads
#include <pthread.h> int pthread_join(pthread_t tid, void **thread_return);pthread_joinblocks until threadtidterminates, assigns the generic (void*) pointer returned by the thread routine to the location pointed to bythread_return, and then reaps any memory resources held by the terminated thread.
- Unlike Linux
wait,pthread_joincan only wait for a specific thread to terminate.
Posix Threads - Detaching Threads
At any point in time, a thread is joinable or detached.
- Joinable Thread
- A joinable thread can be reaped and killed by other threads.
- A joinable thread’s memory resources (such as stack) are not freed until it is reaped by another thread.
- Detached Thread
- A detached thread can’t be reaped or killed by other threads.
- A detached thread’s memory resources are freed automatically by the system when it terminates.
- By default, threads are created joinable. Joinable threads can be detached by a call to the
pthread_detachfunction.#include <pthread.h> int pthread_detach(pthread_t tid);
- Joinable Thread
Posix Threads - Initializing Threads
#include <pthread.h> pthread_once_t once_control = PTHREAD_ONCE_INIT; int pthread_once(pthread_once_t *once_control, void (*init_routine)(void));once_controlis a global variable or static variable that is always initialized to PTHREAD_ONCE_INIT.
- The first time you call
pthread_oncewith an argument ofonce_control, it invokesinit_routine, which is a function with no input arguments that returns nothing.
- Subsequent calls to
pthread_oncewith the sameonce_controlvariable do nothing.
pthred_oncecan used to dynamically initialize global variables that are shared by multiple threads.
A Concurrent Server Based on Threads
#include "csapp.h" void echo(int connfd); void *thread(void *vargp); int main(int argc, char **argv) { int listenfd, *connfdp; socklen_t clientlen; struct sockaddr_storage clientaddr; pthread_t tid; if (argc != 2) { fprintf(stderr, "usage: %s <port>\n", argv[0]); exit(0); } listenfd = Open_listenfd(argv[1]); while (1) { clientlen = sizeof(struct sockaddr_storage); connfdp = Malloc(sizeof(int)); *connfdp = Accept(listenfd, (SA *) &clientaddr, &clientlen); Pthread_create(&tid, NULL, thread, connfdp); } } /* Thread routine */ void *thread(void *vargp) { int connfd = *((int *)vargp); Pthred_detach(pthread_self()); Free(vargp); echo(connfd); Close(connfd); return NULL; }- If you write code as below to pass a pointer to the descriptor :
//... connfd = Accept(listenfd, (SA *) &clientaddr, &clientlen); Pthread_create(&tid, NULL, thread, &connfd); //... void *thread(void *vargp) { int connfd = *((int *)vargp); //... }this code would introduce a race between the assignment statement in the peer thread and the
acceptin the main thread.If the assignment of
connfdcompletes after theaccept, then the localconnfdvariable in the peer threads gets the descriptor number of the next connection.⇒ We must assign each connected descriptor returned by
acceptto its own dynamically allocated memory block.
- We must detach each thread so that its memory resources will be reclaimed when it terminates.
- We must free the memory block that was allocated by the main thread.
- If you write code as below to pass a pointer to the descriptor :
12.4 Shared Variables in Threaded Programs
12.4 Shared Variables in Threaded Programs
Threads Memory Model
- Each threads has its own separate thread context:
- thread ID (TID)
- stack
- stack pointer
- program counter
- condition codes
- general-purpose register values
- Each threads shares the rest of the process context with the other threads:
- The entire user VAS - read-only text (code), read/write data, the heap, and any shared library code and data areas
- Open files
- ⇒ Registers are never shared, whereas VM is always shared.
- Thread stacks are contained in the stack area of VAS, and are usually accessed independently by their respective threads.
However, different thread stacks are not protected from other threads. - A thread can access any part of the stack if it manages to acquire a pointer to another thread’s stack.
- Each threads has its own separate thread context:
Mapping Variables to Memory
- Global variables
- Any variable declared outside of a function.
- At run time, the read/write area of VM contains exactly one instance of each global variable that can be referenced by any thread.
- Local automatic variables
- Variable that is declared inside a function without the
staticattribute.
- Each thread’s stack contains its own instances of any local automatic variables. (Even if multiple threads execute the same thread routine.)
- Variable that is declared inside a function without the
- Local static variables
- Variable that is declared inside a function with the
staticattribute.
- The read/write area of VM contains exactly one instance of each local static variable declared in a program.
- Variable that is declared inside a function with the
- Global variables
Shared Variables
- A variable
vis shared = One of its instances is referenced by more than one thread.
- Example Code
#include "csapp.h" #define N 2 void *thread(void *vargp); char **ptr; /* Global variable */ int main() { int i; pthread_t tid; char *msgs[N] = { "Hello from foo", "Hello from bar" }; ptr = msgs; for (i = 0; i < N; i++) Pthread_create(&tid, NULL, thread, (void *)i); Pthread_exit(NULL); } void *thread(void *vargp) { int myid = (int)vargp; static int cnt = 0; printf("[%d] : %s (cnt=%d)\n", myid, ptr[myid], ++cnt); return NULL; }- Global variables :
ptr
- Local automatic variables :
tid,myid→tid.m,myid.p0,myid.p1
- Local static variables :
cnt
- In line 26 (
printf("[%d] : %s (cnt=%d)\n", myid, ptr[myid], ++cnt);), the peer threads reference the contents of the main thread’s stack indirectly through the globalptrvariable. → Thread stacks are not protected!
cntis shared variable because it has only one run-time instance and this instance is referenced by both peer threads.
myidis not shared because each of its two instances is referenced by exactly one thread.
- Global variables :
- A variable
12.5 Synchronizing Threads with Semaphores
12.5 Synchronizing Threads with Semaphores
Shared Variable Introducing Synchronization Errors
Shared variables can introduce the possibility of nasty synchronization errors. - Consider
badcnt.c/* WARNING: This code is buggy! */ #include "csapp.h" void *thread(void *vargp); /* Thread routine prototype */ /* Global shared variable */ volatile long cnt = 0; /* Counter */ int main(int argc, char **argv) { long niters; pthread_t tid1, tid2; /* Check input argument */ if (argc != 2) { printf("usage: %s <niters>\n", argv[0]); exit(0); } niters = atoi(argv[1]); /* Create threads and wait for them to finish */ Pthread_create(&tid1, NULL, thread, &niters); Pthread_create(&tid2, NULL, thread, &niters); Pthread_join(tid1, NULL); Pthread_join(tid2, NULL); /* Check result */ if (cnt != (2 * niters)) printf("BOOM! cnt=%ld\n", cnt); else printf("OK cnt=%ld\n", cnt); exit(0); } /* Thread routine */ void *thread(void *vargp) { long i, niters = *((long *)vargp); for (i = 0; i < niters; i++) cnt++; return NULL; }- When we run this code, we get wrong answers & different answers each time!
linux> ./badcnt 1000000 BOOM! cnt=1445085 linux> ./badcnt 1000000 BOOM! cnt=1915220- The assembly code for the counter loop
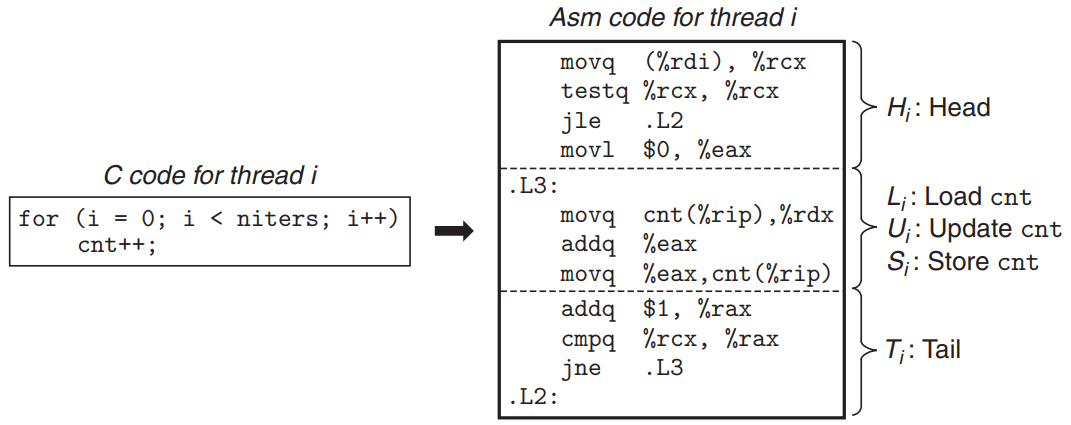
- : loads the shared variable
cntinto the % (value of register %rdx in thread i)
- : updates %
- : stores the updated value of % back to the shared variable
cnt.
- : loads the shared variable
- Each concurrent execution defines some total ordering of the instructions in the two threads.
- There is no way to predict whether the OS will choose a correct ordering for your threads.
Progress Graphs
A progress graph models the execution of n concurrent threads as a trajectory through an n-dimensional Cartesian space.
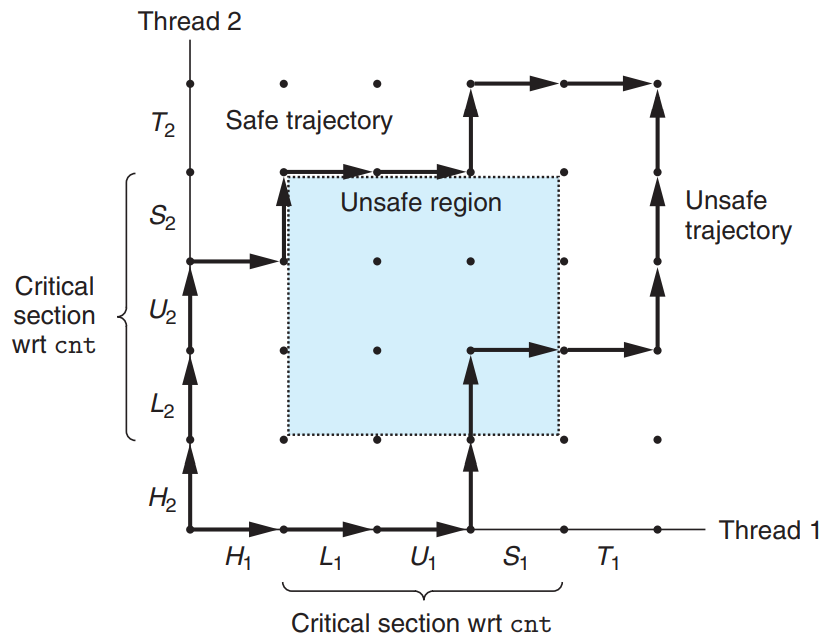
- Each axis k = the progress of thread k
- Each point (, , …, ) = the state where thread k has completed instruction .
- The origin = initial state where none of the threads has yet completed an instruction.
- A directed edge = Instruction execution = A transition from one state to another.
- Trajectory = The execution history of a program
- Critical Section
- For thread i, the instructions (, , ) that manipulate the contents of the shared variable
cntconstitute a critical section.
- Critical section of a thread should not be interleaved with the critical section of the other thread.
- ⇒ Each thread must be ensured to have mutually exclusive access to the shared variable while it is executing the instructions in its critical section.
- For thread i, the instructions (, , ) that manipulate the contents of the shared variable
- Unsafe Region
- Unsafe region = The intersection of the two critical sections.
- The unsafe region abuts, but doesn’t include the states along its perimeter.
- Safe trajectory = A trajectory that skirts the unsafe region. (↔ Unsafe trajectory)
- Any safe trajectory will correctly update the shared counter.
- ⇒ We must synchronize the threads so that they always have a safe trajectory.
Semaphores
A semaphore is a global variable with a nonnegative integer value that can only be manipulated by two special operations, P and V:
-
- If s is nonzero, then P decrements s and returns immediately.
- If s is zero, then suspend the thread until s becomes nonzero and the thread is restarted by a V operation. After restarting, the P decrements s and returns.
-
- Increments s by 1.
- If there are any threads blocked at a P waiting for s to become nonzero, then V restarts exactly one of these threads.
- When several threads are waiting at a semaphore, you can’t predict which one will be restarted as a result of V.
- The test, decrement in P and increment in V occurs indivisibly. (occurs without interruption)
- Semaphore invariant
- The definitions of P and V ensure that a running program can never enter a state where a properly initialized semaphore has a negative value.
- → can control the trajectories of concurrent programs.
- Posix functions for manipulating semaphores
#include <semaphore.h> int sem_init(sem_t *sem, 0, unsigned int value); int sem_wait(sem_t *s); /* P(s) */ int sem_post(sem_t *s); /* V(s) */sem_initinitializes semaphoresemtovalue.
- For conciseness, we use the following equivalent P and V wrapper functions instead:
#include "csapp.h" void P(sem_t *s); /* Wrapper function for sem_wait */ void V(sem_t *s); /* Wrapper function for sem_post */
-
Using Semaphores for Mutual Exclusion
Associate a semaphore s, initially 1, with each shared variable and then surround the corresponding critical section with and operations.
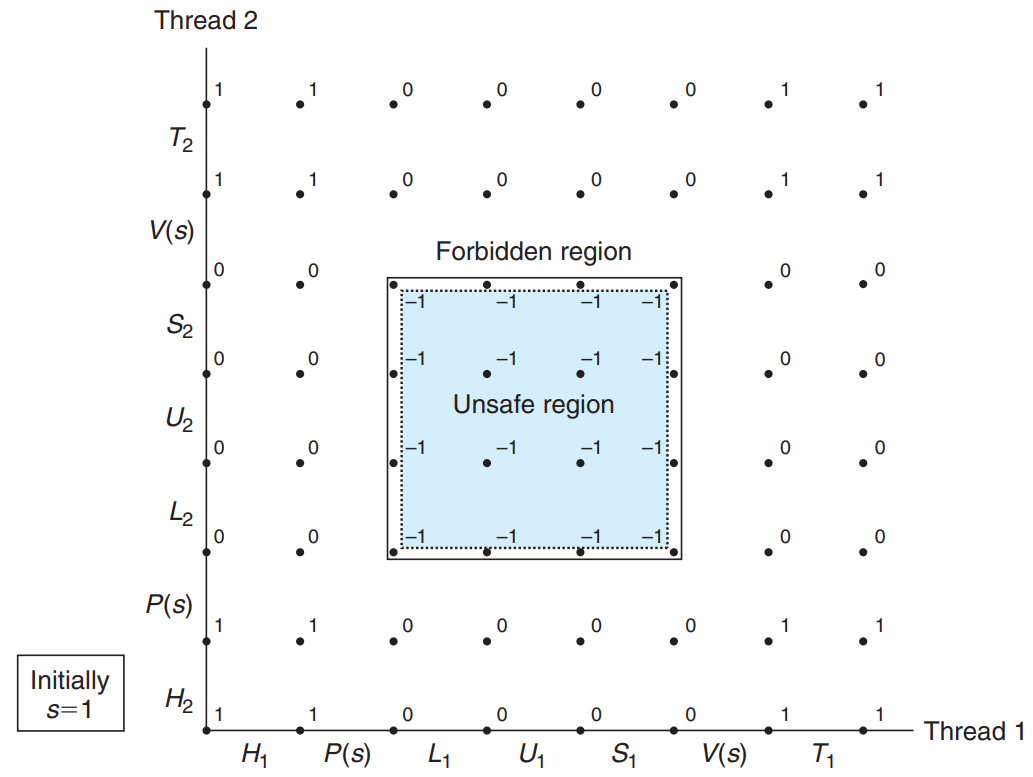
- Mutex : Binary semaphores whose purpose is to provide mutual exclusion.
- Counting Semaphore : A semaphore that is used as a counter for a set of available resources.
- The combination of and creates a collection of states, called a forbidden region, where .
- Because of semaphore invariant → No feasible trajectory can include one of the states in the forbidden region. & The forbidden region completely encloses the unsafe region.
- ⇒ Every feasible trajectory is safe!!
- Synchronizing the example code
volatile long cnt = 0; /* Counter */ sem_t mutex; /* Semaphore that protects counter */ //... Sem_init(&mutex, 0, 1); /* mutex = 1 */ //... for (i = 0; i < niters; i++) { P(&mutex); cnt++; V(&mutex); }
Using Semaphores to Schedule Shared Resources - Producer-Consumer Problem

- The producer thread repeatedly generates new items and inserts them into a bounded buffer with n slots.
- The consumer thread repeatedly removes items from the buffer and then consumes them.
- We must guarantee mutually exclusive access to the buffer & schedule accesses to the buffer. (If the buffer is full, then the producer must wait. & If the buffer is empty, the consumer must wait.)
SBUF: A package for synchronizing concurrent access to bounded buffers.sbuf_t: Bounded buffertypdef struct { int *buf; /* Buffer array */ int n; /* Maximum number of slots */ int front; /* buf[(front+1)%n] is first item */ int rear; /* buf[rear%n] is last item */ sem_t mutex; /* Protects accesses to buf */ sem_t slots; /* Counts available slots */ sem_t items; /* Countes available items */ } sbuf_tmutexprovides mutually exclusive buffer access.
slots&itemsare counting semaphores that count the number of empty slots & available items, respectively.
SBUF#include "csapp.h" #include "sbuf.h" /* Create an empty, bounded, shared FIFO buffer with n slots */ void sbuf_init(sbuf_t *sp, int n) { sp->buf = Calloc(n, sizeof(int)); sp->n = n; /* Buffer holds max of n items */ sp->front = sp->rear = 0; /* Empty buffer iff front == rear */ Sem_init(&sp->mutex, 0, 1); /* Binary semaphore for locking */ Sem_init(&sp->slots, 0, n); /* Initially, buf has n empty slots */ Sem_init(&sp->items, 0, 0); /* Initially, buf has zero data items */ } /* Clean up buffer sp */ void sbuf_deinit(sbuf_t *sp) { Free(sp->buf); } /* Insert item onto the rear of shared buffer sp */ void sbuf_insert(sbuf_t *sp, int item) { P(&sp->slots); /* Wait for available slot */ P(&sp->mutex); /* Lock the buffer */ sp->buf[(++sp->rear)%(sp->n)] = item; /* Insert the item */ V(&sp->mutex); /* Unlock the buffer */ V(&sp->items); /* Announce available item */ } /* Remove and return the first item from buffer sp */ int sbuf_remove(sbuf_t *sp) { int item; P(&sp->items); /* Wait for available item */ P(&sp->mutex); /* Lock the buffer */ item = sp->buf[(++sp->front)%(sp->n)]; /* Remove the item */ V(&sp->mutex); /* unlock the buffer */ V(&sp->slots); /* Announce available slot */ return item; }
Using Semaphores to Schedule Shared Resources - Readers-Writers Problem
- Writers (Threads that modify the shared object) must have exclusive access to the object.
- Readers(Threads that only read the shared object) may share the object with an unlimited number of other readers.
- The first readers-writers problem
- No reader should be kept waiting unless a writer has already been granted permission to use the object.
- = No reader should wait simply because a writer is waiting.
- The second readers-writers problem
- Once a writer is ready to write, it should perform its write ASAP.
- Solution to the first readers-writers problem
/* Global variables */ int readcnt; /* Initially = 0; */ sem_t mutex, w; /* Both initially = 1 */ void reader(void) { while (1) { P(&mutex); readcnt++; if (readcnt == 1) /* First in */ P(&w); V(&mutex); /* Critical Section - Reading happens */ P(&mutex); readcnt--; if (readcnt == 0) /* Last out */ V(&w); V(&mutex); } } void writer(void) { while (1) { P(&w); /* Critical Section - Writing happens */ V(&w); } }
Putting It Together: A Concurrent Server Based on Prethreading
- A prethreaded concurrent echo server
- A server based on prethreading consists of a main thread and a set of worker threads.
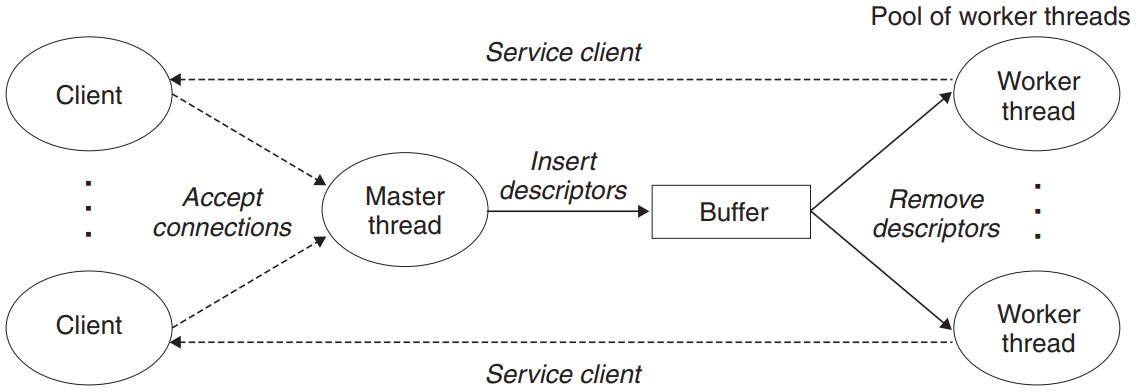
- The main thread repeatedly accepts connection requests from clients and places the resulting connected descriptors in a bounded buffer.
- Each worker thread repeatedly removes a descriptor from the buffer, services the client, and then waits for the next descriptor.
#include "csapp.h" #include "sbuf.h" #define NTHREADS 4 #define SBUFSIZE 16 void echo_cnt(int connfd); void *thread(void *vargp); sbuf_t sbuf; /* Shared buffer of connected descriptors */ int main(int argc, char **argv) { int i, listenfd, connfd; socklen_t clientlen; struct sockaddr_storage clientaddr; pthread_t tid; if (argc != 2) { fprintf(stderr, "usage: %s <port>\n", argv[0]); exit(0); } listenfd = Open_listenfd(argv[1]); sbuf_init(&sbuf, SBUFSIZE); for(i = 0; i < NTHREADS; i++) /* Create worker threads */ Pthread_create(&tid, NULL, thread, NULL); while (1) { clientlen = sizeof(struct sockaddr_storage); connfd = Accept(listenfd, (SA *) &clientaddr, &clientlen); sbuf_insert(&sbuf, connfd); /* Insert connfd in buffer */ } } void *thread(void *vargp) { Pthread_detach(pthread_self()); while (1) { int connfd = sbuf_remove(&sbuf); /* Remove connfd from buffer */ echo_cnt(connfd); /* Service client */ Close(connfd); } }
echo_cnt#include "csapp.h" static int byte_cnt; /* Byte counter */ static sem_t mutex; /* and the mutex that protects it */ static void init_echo_cnt(void) { Sem_init(&mutex, 0, 1); byte_cnt = 0; } void echo_cnt(int connfd) { int n; char buf[MAXLINE]; rio_t rio; static pthread_once_t once = PTHREAD_ONCE_INIT; Pthread_once(&once, init_echo_cnt); /* Initialization */ Rio_readinitb(&rio, connfd); while((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0) { P(&mutex); byte_cnt += n; printf("server received %d (%d total) bytes on fd %d\n", n, byte_cnt, connfd); V(&mutex); Rio_writen(connfd, buf, n); } }echo_cntuses thepthread_onceto call the initialization function the first time some thread calls theecho_cntfunction.- Advantage : it makes the package easier to use. / Disadvantage : Every call to
echo_cntmakes a call topthread_once, which most times does nothing useful.
- Advantage : it makes the package easier to use. / Disadvantage : Every call to
- The access to the shared
byte_cntvariable are protected by P and V operations.
- A prethreaded concurrent echo server
12.6 Using Threads for Parallelism
12.6 Using Threads for Parallelism
Sequential, Concurrent, and Parallel Programs
- Sequential Program : Written as a single logical flow
- Concurrent Program : Written as multiple concurrent flows
- Parallel Program : A concurrent program running on multiple processors
Example Parallel Program -
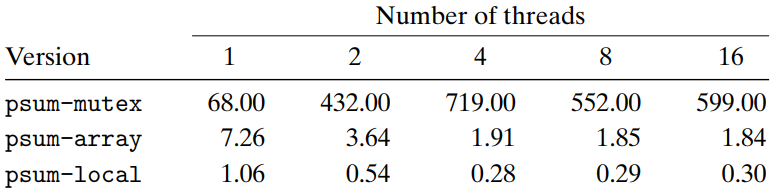
psum-mutex.cPurpose - To sum the sequence of integers 0, …, n - 1 in parallel
→ Partition the sequence into t disjoint regions and then assign each of t different threads to work on its own region.
#include "csapp.h" #define MAXTHREADS 32 void *sum_mutex(void *vargp); /* Thread routine */ /* Global shared variables */ long gsum = 0; /* Global sum */ long nelems_per_thread; /* Number of elements to sum */ sem_t mutex; /* Mutex to protect global sum */ int main(int argc, char **argv) { long i, nelems, log_nelems, nthreads, myid[MAXTHREADS]; pthread_t tid[MAXTHREADS]; /* Get input arguments */ if (argc != 3) { printf("Usage: %s <nthreads> <log_nelems>\n", argv[0]); exit(0); } nthreads = atoi(argv[1]); log_nelems = atoi(argv[2]); nelems = (1L << log_nelems); nelems_per_thread = nelems / nthreads; sem_init(&mutex, 0, 1); /* Create peer threads and wait for them to finish */ for (i = 0; i < nthreads; i++) { myid[i] = i; Pthread_create(&tid[i], NULL, sum_mutex, &myid[i]); } for (i = 0; i < nthreads; i++) Pthread_join(tid[i], NULL); /* Check final answer */ if (gsum != (nelems * (nelems-1))/2) printf("Error: result=%ld\n", gsum); exit(0); } /* Thread routine for psum-mutex.c */ void *sum_mutex(void *vargp) { long myid = *((long *)vargp); /* Extract the thread ID */ long start = myid * nelems_per_thread; /* Start element index */ long end = start + nelems_per_thread; /* End element index */ long i; for (i = start; i < end; i++) { P(&mutex); gsum += i; V(&mutex); } return NULL; }- Performance (running time in seconds)

- Poor performance ← The synchronization operations (P and V) are very expensive relative to the cost of a single memory update.
- ⇒ Synchronization overhead is expensive and should be avoided if possible.
- Performance (running time in seconds)
Avoiding Synchronization -
psum-array.c,psum-local.cTo avoid synchronization, have each peer thread compute its partial sum in a private variable that isn’t shared with any other thread.
/* Thread routine for psum_arrayc.c */ void *sum_array(void *vargp) { long myid = *((long *)vargp); /* Extract the thread ID */ long start = myid * nelems_per_thread; /* Start element index */ long end = start + nelems_per_thread; /* End element index */ long i; for (i = start; i < end; i++) { psum[myid] += i; } return NULL; }- Each peer thread has a unique memory location to update → it is not necessary to protect these updates with mutexes!
- Only necessary synchronization : Main thread must wait for all of the children to finish. → Finally, the main thread sums up the elements of the
psumvector to arrive at the final result.
- Further optimization - Eliminating unnecessary memory references (
psum-local.c)for(i = start; i < end; i++) { sum += i; } psum[myid] = sum;
- Performance (running time in seconds)
Characterizing the Performance of Parallel Programs
- Performance of
psum-local.c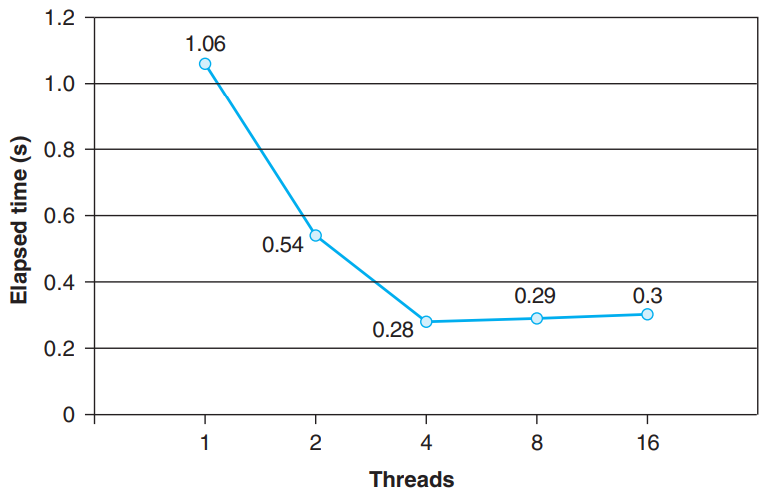
- Running time decreases as we increase the number of threads, up to 4 threads.
- Running time increases a bit as we increase the number of threads because of the overhead of context switching multiple threads on the same core.
- ⇒ Parallel programs are often written so that each core runs exactly one thread.
- Speedup of a parallel program (Strong Scaling)
- ( = # of processor cores and = the running time on k cores)
- = Execution time of a sequential version of the program → = Absolute speedup
- = Execution time of a parallel version of the program running on one core → = Relative speedup
- Absolute speedup is truer measure of the benefits of parallelism. (Synchronization overheads can artificially inflate the relative speedup.)
- Absolute speedup is more difficult to measure - it requires two different versions of the program.
- Efficiency of a parallel program
- Efficiency is a measure of the overhead due to parallelization. Programs with higher efficiency are spending more time doing useful work and less time synchronizing and communicating.
- (typically reported as a percentage in the range (0, 100].)
- Weak Scaling
- Weak scaling increases the problem size along with the # of processors, such that the amount of work performed on each processor is held constant as the # of processor increases.
- Speedup and efficiency are expressed in terms of the total amount of work accomplished per unit.
- A truer measure than strong scaling - it more accurately reflects our desire to use bigger machines to do more work.
- For applications whose sizes are not so easily increased, strong scaling is more appropriate.
- Performance of
12.7 Other Concurrency Issues
12.7 Other Concurrency Issues
Threads Safety
Thread-safe ↔ The function will always produce correct results when called repeatedly from multiple concurrent threads.
Classes of thread-unsafe functions:
- Class 1: Functions that do not protect shared variables
- To make this class of thread-unsafe functions thread-safe, protect the shared variables with synchronization operations such as P & V.
- Class 2: Functions that keep state across multiple invocations
unsigned next_seed = 1; /* rand - return pseudorandom integer in the range 0..32767 */ unsigned rand(void) { next_seed = next_seed*1103515245 + 12543; return (unsigned)(next_seed>>16) % 32768; } /* srand - set the initial seed for rand() */ void srand(unsigned new_seed) { next_seed = new_seed; }- The result of the current invocation of
randdepends on an intermediate result from the previous iteration.→ Can’t predict the result when multiple threads are calling
rand.
- To make this class of thread-unsafe functions thread-safe, rewrite it so that it doesn’t use any
staticdata, relying instead on the caller to pass the state information in arguments.
- The result of the current invocation of
- Class 3: Functions that return a pointer to a static variable
- The results of the functions being used by one thread can be silently overwritten by another thread. (example :
ctime,gethostbyname)
- To make these functions thread-safe, rewrite the function so that the caller passes the address of the variable in which to store the results.
- Or use the lock-and-copy technique: associate a mutex with the thread-unsafe function.
- At each call site, lock the mutex → call the thread-unsafe function → copy the result returned by the function to a private memory location → unlock the mutex.
- Define a thread-safe wrapper function that performs the lock-and-copy.
- Thread-safe wrapper function for the C standard library
ctimefunction
char *ctime_ts(const time_t *timep, char *privatep) { char *sharedp; P(&mutex); sharedp = ctime(timep); strcpy(privatep, sharedp); /* Copy string from shared to private */ V(&mutex); return privatep; } - The results of the functions being used by one thread can be silently overwritten by another thread. (example :
- Class 4: Functions that call thread-unsafe functions
- If a function calls class 2 function : The caller is also thread-unsafe.
- If a function calls class 1 or class 3 function : The caller can still be thread-safe if you protect the call site and any resulting shared data with a mutex.
- Class 1: Functions that do not protect shared variables
Reentrancy
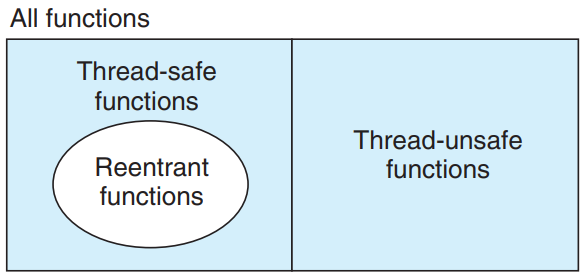
Reentrant functions are functions that do not reference any shared data when they are called by multiple threads.
- The set of reentrant functions is a proper subset of the thread-safe functions.
- Reentrant functions are typically more efficient than non-reentrant thread-safe functions - they require no synchronization operations.
- The only way to convert a class 2 thread-unsafe function into a thread-safe one is to rewrite it so that it is reentrant.
- Example Code - Reentrant version of the
rand/* rand_r - return a pseudorandom integer on 0..32767 */ int rand_r(unsigned int *nextp) { *nextp = *nextp * 1103515245 + 12345; return (unsigned int)(*nextp / 65536) % 32768; }
- If all function arguments are passed by value (= no pointers) & all data references are to local automatic stack variables (= no references to static or global variables), the function is explicitly reentrant.
- If some parameters in otherwise explicitly reentrant function are passed by reference (= passing pointers), the function is implicitly reentrant - it is only reentrant if the calling threads are careful to pass pointers to nonshared data.
Using Existing Library Functions in Threaded Programs
- Common thread-unsafe library functions
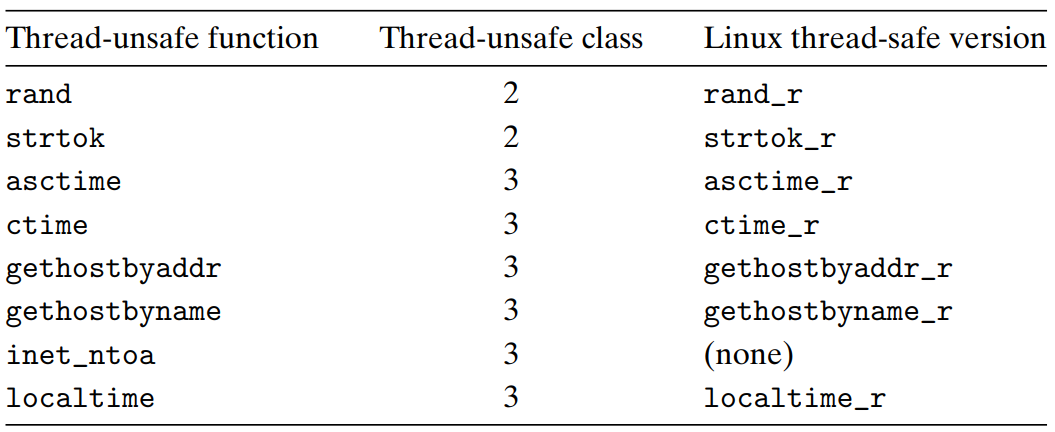
- To call one of these functions, use lock and copy technique.
- Lock and copy approach’s disadvantages
- Additional synchronization slows down the program.
- Functions that return pointers to complex structures of structures require a deep copy of the structures to copy the entire structure hierarchy.
- Lock-and-copy approach won’t work for a class 2 thread-unsafe function.
- Common thread-unsafe library functions
Races
A race occurs when the correctness of a program depends on one thread reaching point x in its control flow before another thread reaches point y.
- Example Code - A program with a race
/* WARNING: This code is buggy! */ #include "csapp.h" #define N 4 void *thread(void *vargp); int main() { pthread_t tid[N]; int i; for (i = 0; i < N; i++) Pthread_create(&tid[i], NULL, thread, &i); for (i = 0; i < N; i++) Pthread_join(tid[i], NULL); exit(0); } /* Thread routine */ void *thread(void *vargp) { int myid = *((int *)vargp); printf("Hello from thread %d\n", myid); return NULL; }- A race is between each peer thread’s dereferencing and assignment of the argument and the main thread’s next increment of
i.
- If the main thread increments
ibefore the peer thread dereference and assignvargptomyid,myidwill contain the ID of some other thread.
- To eliminate the race, dynamically allocate a separate block for each integer ID and pass the thread routine a pointer to this block.
#include "csapp.h" #define N 4 void *thread(void *vargp); int main() { pthread_t tid[N]; int i, *ptr; for (i = 0; i < N; i++) { ptr = Malloc(sizeof(int)); *ptr = i; Pthread_create(&tid[i], NULL, thread, ptr); } for (i = 0; i < N; i++) Pthread_join(tid[i], NULL); exit(0); } /* Thread routine */ void *thread(void *vargp) { int myid = *((int *)vargp); Free(vargp); printf("Hello from thread %d\n", myid); return NULL; } - A race is between each peer thread’s dereferencing and assignment of the argument and the main thread’s next increment of
- Example Code - A program with a race
Deadlocks
Deadlock is a kind of run-time error, where a collection of threads is blocked, waiting for a condition that will never be true.
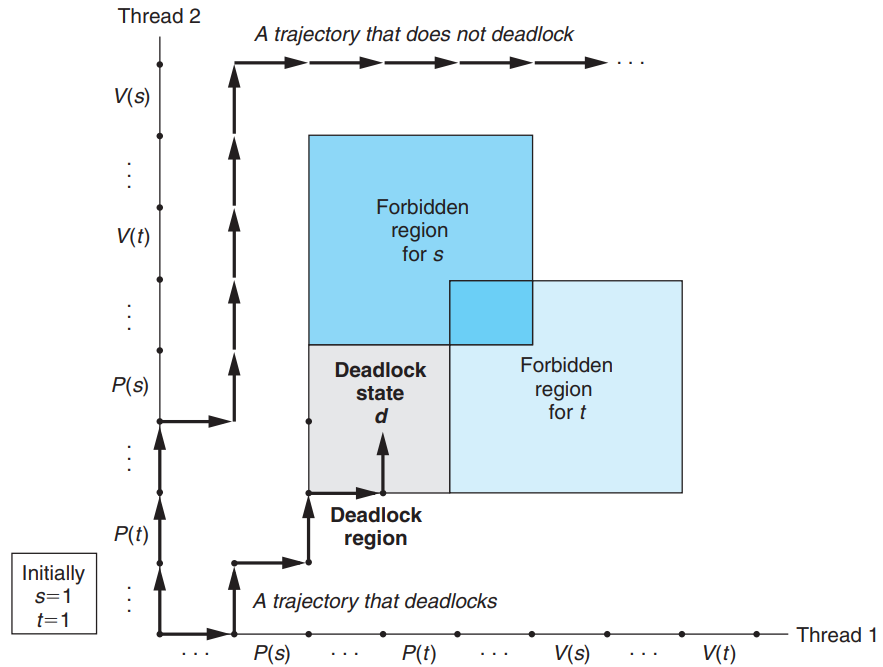
- The programmer has incorrectly ordered the P & V operations → The forbidden regions for the two semaphores overlap. → The deadlock region is created.
- If a trajectory touch a state in the deadlock region, deadlock is inevitable: No further progress is possible because the overlapping forbidden regions block progress in every legal direction.
- Deadlock is not always predictable - It doesn’t happen every time, or in every machine.
- When binary semaphores are used for mutual exclusion, apply the Mutex lock ordering rule to prevent deadlocks:
Mutex lock ordering rule : Given a total ordering of all mutexes, a program is deadlock-free if each thread acquires its mutexes in order and releases them in reverse order.
Leave a comment